



本篇學習筆記將要示範如何使用 Python 來執行 網路爬蟲 web crawler,並以爬取雅虎奇摩電影的「每週新片」頁面資訊為例。筆記包含以下部分:(1)解讀網頁資訊 (2) 萃取資訊 (3) 將資訊整理成data frame (4) 將電影爬蟲寫成函式 (5) 自動化判斷所有分頁url並套用電影爬蟲函數。
(1) 解讀網頁資訊
載入所需套件
|
1 2 3 4 |
# import libraries import pandas as pd import requests from bs4 import BeautifulSoup |
指定URL資訊
|
1 2 3 4 5 6 |
# 指定所要爬網的URL url = 'https://movies.yahoo.com.tw/movie_thisweek.html' # GET request from url and parse via BeautifulSoup r = requests.get(url) # 擷取request回傳的文字部分 web_content = r.text |
解讀(parse)網頁HTML
|
1 2 |
# 使用BeautifulSoup來parse HTMl soup = BeautifulSoup(web_content,'lxml') |
(2) 將「每週新片」的中英文片名、電影介紹、預告片連結爬下來
2-1. 中英文片名
先找到中英文片名在html架構中的規則(可右鍵點擊感興趣物件,並選擇「檢查」)(如下圖)。
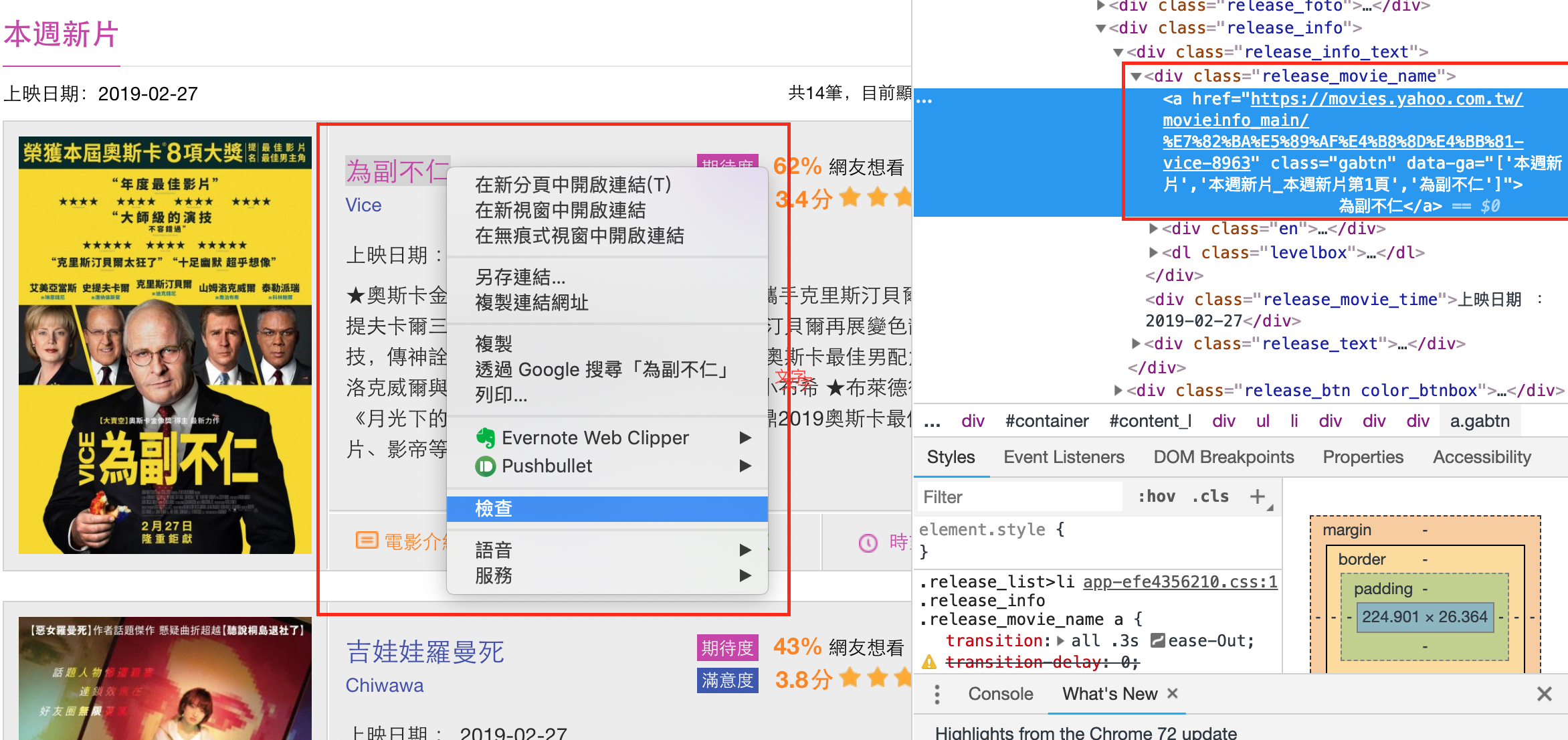
並使用.find_all()找出soup中物件為’div’且class_類別為”release_movie_name”的所有元素,集結成一個list (named newMovie2),每個元素彼此使用逗號間隔。
|
1 2 |
newMovie2 = soup.find_all('div', class_ = "release_movie_name") newMovie2 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 |
[ 為副不仁 期待度 62% 網友想看 滿意度 0分 吉娃娃羅曼死 期待度 43% 網友想看 滿意度 0分 酷寒殺手 期待度 87% 網友想看 滿意度 0分 法律女王 期待度 78% 網友想看 滿意度 0分 恭喜八婆 期待度 88% 網友想看 滿意度 0分 非.虛構情事 期待度 23% 網友想看 滿意度 0分 地獄自拍 期待度 57% 網友想看 滿意度 0分 證人 期待度 96% 網友想看 滿意度 0分 溫泉屋小女將 期待度 80% 網友想看 滿意度 0分 密弑遊戲 期待度 84% 網友想看 滿意度 0分 |
但每個class = ”release_movie_name”的元素中,並不是每個標籤都是我們感興趣的,為了萃取感興趣資訊,我們再從newMovies2 list中,一個一個元素去找出class = ‘gabtn’ 的標籤中的文字(如下段落所示),並將換行與空白字符取消,存取成一個新的list (named NameCHs)。
gabtn” data-ga=”[‘本週新片’,’本週新片_本週新片第1頁’,’密弑遊戲’]”
href=”https://movies.yahoo.com.tw/movieinfo_main/
%E5%AF%86%E5%BC%91%E9%81%8A%E6%88%B2-escape-room-9572″>密弑遊戲
|
1 2 |
NameCHs = [t.find('a', class_='gabtn').text.replace('\n','').replace(' ','') for t in newMovie2] NameCHs |
|
1 2 3 4 5 6 7 8 9 10 |
['為副不仁', '吉娃娃羅曼死', '酷寒殺手', '法律女王', '恭喜八婆', '非.虛構情事', '地獄自拍', '證人', '溫泉屋小女將', '密弑遊戲'] |
同理,找出英文片名的文字。
|
1 2 |
NameENs = [t.find('div', class_='en').find('a').text.replace('\n','').replace(' ','') for t in newMovie2] NameENs |
|
1 2 3 4 5 6 7 8 9 10 |
['Vice', 'Chiwawa', 'ColdPursuit', 'OntheBasisofSex', 'MissBehavior', 'Non-fiction', 'SelfieFromHell', 'InnocentWitness', 'Okko’sInn', 'EscapeRoom'] |
2-2. 預告片連結
一樣,檢視感興趣目標在HTML中的結構規則。
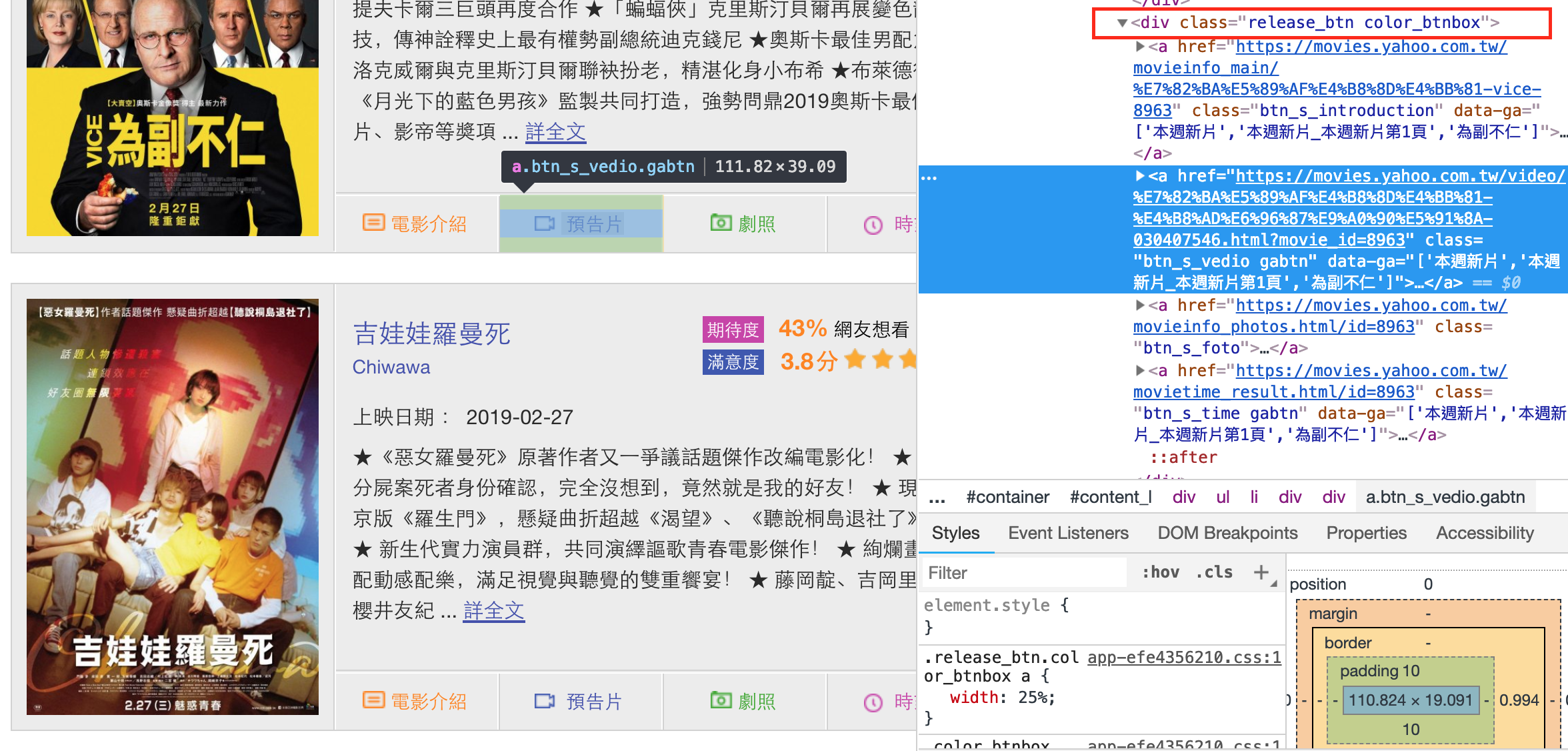
找出所有class_為release_btn color_btnbox的div。
|
1 2 |
newMovie3 = soup.find_all('div',class_="release_btn color_btnbox") newMovie3 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 |
並從newMovie3 list中,進一步取出元素中class_為btn_s_vedio gabtn連結標籤中的連結href。
|
1 2 |
links = [t.find('a',class_="btn_s_vedio gabtn")['href'] for t in newMovie3] links |
|
1 2 3 4 5 6 7 8 9 10 |
['https://movies.yahoo.com.tw/video/%E7%82%BA%E5%89%AF%E4%B8%8D%E4%BB%81-%E4%B8%AD%E6%96%87%E9%A0%90%E5%91%8A-021801838.html?movie_id=8963', 'https://movies.yahoo.com.tw/video/%E5%90%89%E5%A8%83%E5%A8%83%E7%BE%85%E6%9B%BC%E6%AD%BB-%E7%B2%BE%E5%BD%A9%E7%89%87%E9%A0%AD%E6%90%B6%E5%85%88%E7%9C%8B-090102582.html?movie_id=9256', 'https://movies.yahoo.com.tw/video/%E9%85%B7%E5%AF%92%E6%AE%BA%E6%89%8B-%E4%B8%AD%E6%96%87%E9%A0%90%E5%91%8A-105035779.html?movie_id=9377', 'https://movies.yahoo.com.tw/video/%E6%B3%95%E5%BE%8B%E5%A5%B3%E7%8E%8B-%E6%9C%80%E6%96%B0%E9%A0%90%E5%91%8A-093658482.html?movie_id=9389', 'https://movies.yahoo.com.tw/video/%E6%81%AD%E5%96%9C%E5%85%AB%E5%A9%86-%E6%9C%80%E6%96%B0%E9%A0%90%E5%91%8A-025738371.html?movie_id=9432', 'https://movies.yahoo.com.tw/video/%E9%9D%9E-%E8%99%9B%E6%A7%8B%E6%83%85%E4%BA%8B-%E4%B8%AD%E6%96%87%E9%A0%90%E5%91%8A-023735492.html?movie_id=9475', 'https://movies.yahoo.com.tw/video/%E5%9C%B0%E7%8D%84%E8%87%AA%E6%8B%8D-%E6%9C%80%E6%96%B0%E9%A0%90%E5%91%8A-144352730.html?movie_id=9494', 'https://movies.yahoo.com.tw/video/%E8%AD%89%E4%BA%BA-%E5%82%AC%E6%B7%9A%E9%9F%B3%E6%A8%82%E7%89%88%E9%A0%90%E5%91%8A-231957458.html?movie_id=9552', 'https://movies.yahoo.com.tw/video/%E6%BA%AB%E6%B3%89%E5%B1%8B%E5%B0%8F%E5%A5%B3%E5%B0%87-%E4%B8%AD%E6%96%87%E9%A0%90%E5%91%8A-105610983.html?movie_id=9562', 'https://movies.yahoo.com.tw/video/%E5%AF%86%E5%BC%91%E9%81%8A%E6%88%B2-%E4%B8%AD%E6%96%87%E9%A0%90%E5%91%8A-100235196.html?movie_id=9572'] |
2-3. 電影介紹文
檢查介紹文的HTML規則,發現介紹文會夾帶在class = ‘release_text’的div中。
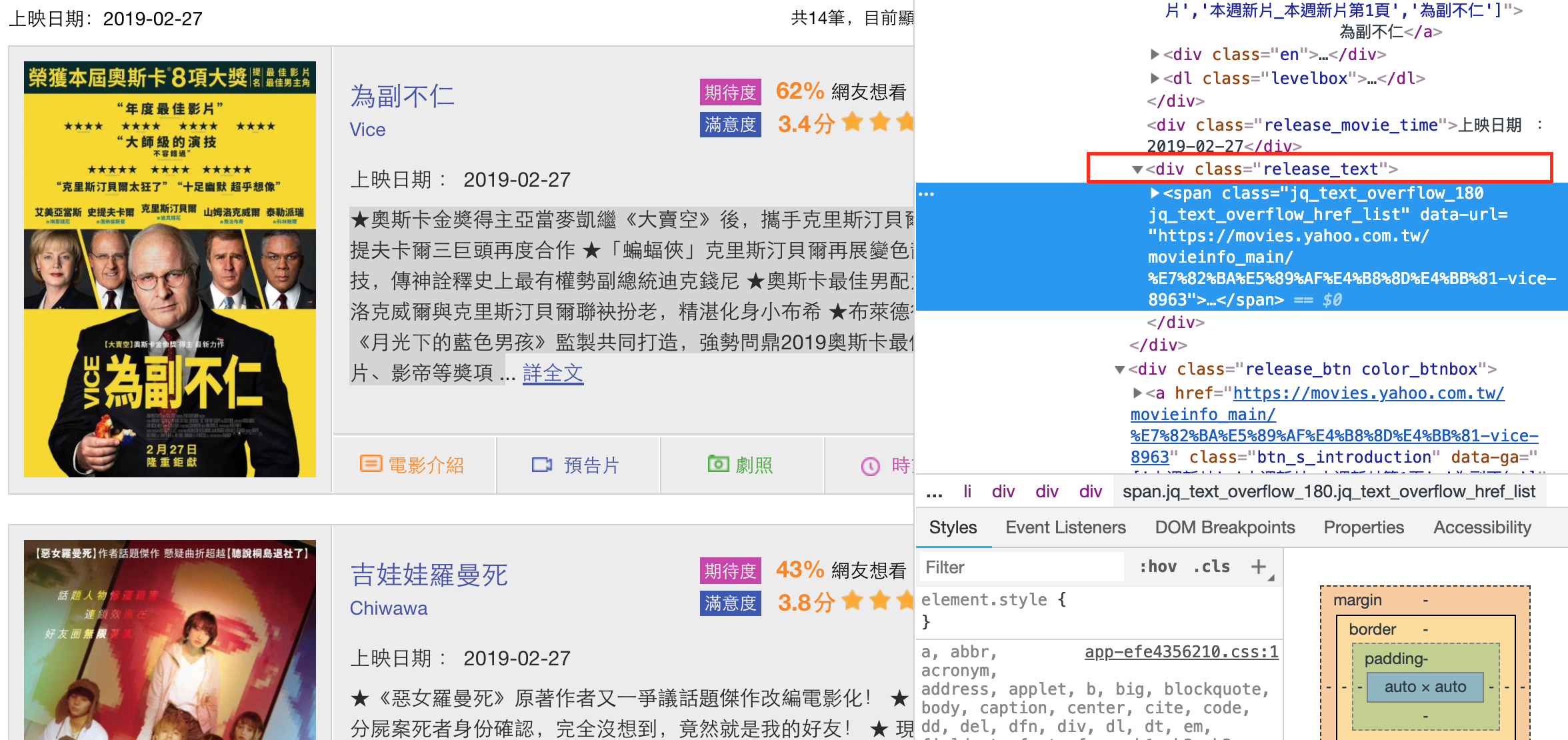
|
1 2 |
newMovie4 = soup.find_all('div',class_="release_text") newMovie4 |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 |
[ ★奧斯卡金獎得主亞當麥凱繼《大賣空》後,攜手克里斯汀貝爾、史提夫卡爾三巨頭再度合作 ★「蝙蝠俠」克里斯汀貝爾再展變色龍演技,傳神詮釋史上最有權勢副總統迪克錢尼 ★奧斯卡最佳男配角山姆洛克威爾與克里斯汀貝爾聯袂扮老,精湛化身小布希 ★布萊德彼特與《月光下的藍色男孩》監製共同打造,強勢問鼎2019奧斯卡最佳影片、影帝等獎項! 《為副不仁》講述美國史上最有權勢的副總統迪克錢尼(克里斯汀貝爾 飾),如何從白宮幕僚逐漸爬上權力的頂峰,成為全世界最有權勢的人--美國總統小布希(山姆洛克威爾 飾)的副手,以及他的政策如何重塑美國並影響至今我們身處的世界。 ★《惡女羅曼死》原著作者又一爭議話題傑作改編電影化! ★ 殺人分屍案死者身份確認,完全沒想到,竟然就是我的好友! ★ 現代東京版《羅生門》,懸疑曲折超越《渴望》、《聽說桐島退社了》! ★ 新生代實力演員群,共同演繹謳歌青春電影傑作! ★ 絢爛畫面搭配動感配樂,滿足視覺與聽覺的雙重饗宴! ★ 藤岡靛、吉岡里帆、櫻井友紀、白石和彌等日本影視圈名人爭相力讚! 話題人物慘遭殺害,連鎖效應在好友圈無限蔓延 一群揮霍青春的青年男女,其中一位長相可愛貌美,猶如眾人「吉祥物」般存在、暱稱為「吉娃娃」的20歲少女,某天驚傳遭人分屍的命案,部分屍體並在東京灣尋獲。她周遭的好友們,開始聚在一起回憶青春,緬懷他們心目中的吉娃娃。大家這時才發現,根本沒人知道她的真名、境遇還有真正的個性。原來在大家對她毫無了解的情況下,她就跟眾人混在一起、談戀愛、甚至發生性關係。究竟真正的「吉娃娃」,到底是位什麼樣的女孩呢? 【關於電影】 《惡女羅曼死》作者話題傑作,懸疑曲折超越《聽說桐島退社了》 《吉娃娃羅曼死》改編自日本知名漫畫家岡崎京子的短篇漫畫作品。曾打造《惡女羅曼死》等轟動不已作品的岡崎京子,特別擅長描繪情慾與悖德,並透過毫無忌諱的性愛場面表現人物內在。這部短篇漫畫,終於在2019年翻拍成劇情長片登上大銀幕。全片描述個性活潑好動、集萬千寵愛於一身的20歲美少女「吉娃娃」,某天竟被殘忍分屍,而她的遭遇也在朋友圈中引發連鎖效應。眾人開始回想自己與「吉娃娃」的每個相處細節,竟發現自己連她的本名、境遇與背景都不知道。也因為好友們各說各話,在不同說法中拼湊出吉娃娃的生活與背景,更讓本片頗有現代女性版《羅生門》的懸疑性,更猶如《渴望》、《聽說桐島退社了》的加乘綜合版。 本片找來曾執導《裸睡美人》的二宮健擔任導演。二宮導演透露,親手拍攝《吉娃娃羅曼史》的真人電影版,一直是他給自己設立的目標,他並回憶:「初次拜讀原作,是我22歲剛從大阪到東京來的時候。那時我雖然想在東京拍攝更大規模的電影,卻諸事不順;即便想讓自己做些什麼,到頭來總是繞回原點,恰好就是那樣的時期,讓我遇到了這部作品。」他並補充:「只花34頁篇幅描繪的青春群像劇,卻帶來非常大的震撼。這群想試著跨越些什麼而掙扎的人物,逐漸跟我的自身形象交疊,以致於在看完原作的瞬間,我就決定要把這部作品給拍成電影。」值得一提的是,二宮導演的作品總有著最前衛的影像,以及動感的配樂,讓他的導演風格非常鮮明並深受好評。尤其本片的派對群戲眾多,導演這次也採用讓演員自由發揮的即興表演,再由鏡頭一一收錄,讓全片的派對、玩樂、性愛等場面顯得特別真實。 本片演員也是一時之選,找來2019年新科藍絲帶獎影后門脇麥擔綱演出「美樹」這個角色,而讀完劇本的她也覺得「非常有趣,很想試試看」而馬上答應邀約。至於靈魂人物「吉娃娃」,則找來新銳女星吉田志織擔綱。她獨特又魅力十足,時而無邪、時而深沉,立體的人物塑造和強烈的存在感,讓人簡直無法相信這是她的首部主演作品。此外,本片也集結成田凌、寬一郎、村上虹郎、玉城蒂娜、栗山千明、淺野忠信等多位新銳、資深實力派演員共同演繹,聯手呈現年輕人面對愛情、金錢、嫉妒、慾望等如夢境般閃亮不已的絢爛青春世界。而全片所勾勒「青春的爆發」與「告終的覺悟」,導演也精準使用過去日本電影從未有過的影像與音樂勾勒出來,勢必滿足觀眾視覺與聽覺的雙重享受,一同進入青春大無畏的美麗與哀愁! ★2019開春最受期待復仇爽片! 冷暴力美學、血花散遍! ★地表最強老爸-連恩尼遜,重拾槍火即刻開戰! 復仇是人性最原始的反撲! 殺我兒,我滅你全團! 剷雪車司機-尼爾剛獲頒榮譽市民表揚,卻收到兒子吸毒致死的訊息,讓他生活頓時起了波瀾。他堅信兒子清白,便開始追查,赫然發現幕後有黑道組織操刀,他從朋友手中獲得黑道兇嫌名單,並依姓名順序送凶手上斷頭台。冰天雪地中,黑道們一個個死於非命,尼爾的復仇行為讓毒梟跟槍火幫派,以為是雙方在找麻煩,進而引發兩個幫派大火拼。為了幫兒子報仇,尼爾也陷入這場世紀廝殺中,雙方頓時火力全開,復仇計畫大快人心… 【幕後花絮】 《酷寒殺手》翻拍自爛番茄新鮮度90%超強好評《該死的順序》,導演漢斯彼得穆蘭開創新暴力美學風格,電影公司買下版權後並無改換導演,仍由漢斯繼續拍攝美語版本,融入更多美式暴力作風。導演當時會想拍這部片,是來自本身被霸凌的怨念:「我從小就喜歡報仇,只要有人欺負我,我就會反擊。」導演認為,復仇是人類非常原始的直覺,儘管沒有達到報仇目的,也能享受到樂趣。 《該死的順序》當年在柏林影展首映之後,全球影評佳評如潮!帝國雜誌給予極高的讚賞,「這才是我們期待已久的復仇爽片!」知名影評網站爛番茄新鮮度近90%超強好評!國際評論對於《該死的順序》師法柯恩兄弟,也超越昆汀塔倫提諾和盧貝松的暴力美學大加讚揚! 片商看中電影超強口碑便著手進行翻拍,將新暴力美學旋風帶入好萊塢;找來具有票房號召力男星-連恩尼遜擔任片中的復仇老爸。雖然連恩尼遜演出這類型的電影並不陌生,但在新片中,導演讓連恩尼遜有更多的內心戲與謀略策畫,他也不再英勇無敵,沒有特務、警察等背景,單純是一位平凡的復仇父親。 在製作方面,麥可雪恩伯格曾擔任過《決殺令》製片,負責本片的暴力美學演繹,而《疾速救援》製片-麥可德雷爾,則擔綱起片中動作炫技保證,讓電影《酷寒殺手》重新定義暴力極致。 ★真人實事改編 一生致力平權 美國傳奇女法官成功奇蹟登上大銀幕 ★《愛的萬物論》金獎提名費莉絲蒂瓊斯X《以你的名字呼喚我》艾米漢默 聯手主演 ★《彗星撞地球》票房女導演咪咪蕾德 睽違大銀幕多年最新力作 ★為信念奮鬥不懈 為歧視挺身而出 繼《永不妥協》後又一激勵人心銀幕佳作 ★故事主角露絲拜德金斯伯格 親自客串演出 「如果連法律都不能一視同仁,兩性如何平權?」取材自現今美國最高法院唯二女大法官露絲拜德金斯伯格(菲莉絲蒂瓊斯 飾)的真實成功故事,本片聚焦在年紀輕輕、剛踏出法學院校門的她,如何在男性至上、女性不被重視的工作環境中,力爭上游成為律師,為兩性爭取平權,成為美國史上最有影響力的法官之一,現在仍任職於最高法院大法官。 ★2019開年最爆笑噴飯喜劇,香港鬼才彭浩翔瘋狂作品,《春嬌與志明》班底火力全開,一定要你笑翻天 ★ 香港最不可思議的八婆女星大集合,為了一瓶奶!?展開瘋狂大作戰 由8個閨密組成的「八婆」whatsapp群組,因彼此的恩怨,讓群組不再對話。 而June也在認識了現在的老公後,漸漸疏遠其他7位閨密。她的女魔頭上司最近生了小孩,需要定時抽母奶放進冰箱。沒想到,June竟然誤把母奶加進咖啡裡,還被大老闆喝個精光,要是被發現肯定工作不保。 情急之下,她只好找回很久沒聯絡的群組成員,希望在下班前,幫忙找到母奶頂替。此時,即將襲港的颱風逼近,交通大亂,八婆們能否在時間之內,完成尋奶任務呢? 亞倫是法國出版界的風雲人物,然而時代在變,亞倫也忙於適應電子世代帶給出版業的衝擊,他不僅要學習如何發行電子書,就連讀者的消費取向也令他匪夷所思。人氣博主、暢銷部落客只要將在社群媒體發表的短文集結成冊,也能成為暢銷書?亞倫拒絕出版與他年紀相仿且合作多年的作家李奧納多的新書,他的作品寫得多半是自己的真實經驗,再將筆下人物稍加改名換姓,他的前妻、前任女友以及被影射的周遭人物深受其擾。這次的新書是李奧納多跟某個名人芝麻綠豆般的緋聞軼事,亞倫質疑他根本沒有創意以及想像力,然而出人意表的是亞倫身為名人的妻子卻認為這是李奧納多最好的作品… 曾經榮獲坎城影展最佳導演、法國中生代最知名的導演奧利維耶阿薩亞斯今年入圍威尼斯影展競賽之作,這也是他與茱麗葉畢諾許第三度合作。導演精心設計的日常對話,涵蓋文化、民主、政治以及時事等多面向,幽默諷刺又饒富哲學寓意,尤其對現實世界女明星茱麗葉畢諾許的一番嘲弄,令人會心一笑。茱麗葉畢諾許與吉翁卡列精彩的演出令人驚艷。 【關於電影】 強勢挑戰大時代議題 阿薩亞斯回歸16釐米力抗數位狂潮 《非.虛構情事》講述近年討論度最高的議題之一——傳統紙本出版業與電子書的價值觀拉扯。在銳不可擋的現代數位化潮流當中,阿薩亞斯從未停止關注紙本書出版面臨到的夕陽產業議題,延續了過去作品《夏日時光》、《星光雲寂》中對於全球化、經濟、科技以及文化在時代下變遷的討論,從個人及群體角度出發,採用了輕鬆幽默卻又充滿哲學性的論調,讓觀眾能夠輕巧的進入議題核心。本片透過絕妙對話──無論是兩人世界或是團體聚會,還是身為編輯與明星、作家與政治狂熱組合的夫妻檔、偷情對象、工作夥伴──建構出不同背景的人們處於變遷的世界中,被傳統以及新潮拉扯的糾結感。另外,在片中描述面對現代化的掙扎時,阿薩亞斯的敘事角度選擇欣然理解當前數位化的崇高地位,但在技術方面卻選擇回歸以16釐米膠捲拍攝,盼望以創作初衷,在與資本主義的抗衡中找到更多討論空間。 被問到劇中作家因大量採用自身故事作為創作題材而備受爭議,阿薩亞斯笑說:「我應該比他有道德一點吧!」法文片名原意為「雙面人生」,跟英文片名「非.虛構情事」交錯出真實與虛構從來就無法完全切割的深層寓意;電影中出版社提議可以找大明星茱麗葉畢諾許來為有聲書配音,以刺激銷量,飾演女主角瑟琳娜的正是茱麗葉本人,她在片中神回覆「我認識她的經紀人,或許可以關說一下」。劇中被嘲諷的茱麗葉畢諾許同時活靈活現地存在在電影裡,「故事無非就是現實生活的一面鏡子啊」。 阿薩亞斯三度合作大滿貫影后 全新卡司歡樂滿堂 茱麗葉畢諾許的影后身影無庸置疑是片中一大亮點,《非.虛構情事》是她第三次與阿薩亞斯合作,相知多年的兩人早有絕佳默契,阿薩亞斯受訪時表示:「她的不羈、詼諧都讓我的靈感源源不絕。」並認為只有她能夠讓瑟琳娜的幽默立體化;而曾被封為法國最帥男演員的吉翁卡列則是在阿薩亞斯寫作過程中逐漸成形的想法,認為身為這一代最有代表性的男演員之一,只有他有資格撐得起這個角色的權威感,成功吸引觀眾的目光;而出身舞台劇演員及導演的文森馬格恩也自帶氣場,讓劇中金牌編輯與風流作家的對手戲,與吉翁卡列第一次合作就激盪出充滿電力的精彩火花。 除了茱麗葉畢諾許與阿薩亞斯以外,其他卡司皆是首度合作,但執導過程中,阿薩亞斯忍不住盛讚演員們,「比我更清楚如何演繹出腳本中的幽默,甚至共鳴出新的層次!」 ★ 改編自2015年在YouTube創下逾2000萬次點閱同名恐怖短片 ★ 《愛殺瑪莉》製片群傾力打造,驚嚇程度直逼《鬼關燈》《陰兒房》! ★ 21世紀的科技驚悚預言,直達地獄的恐怖自拍! ★ 新世紀文明病,這次真的會送命! 德國部落客茱莉亞來到美國拜訪她的姪女漢娜,卻在抵達後突然怪病纏身,臥床不起。漢娜家也開始接二連三地出現各種不尋常的超自然現象,不堪其擾的漢娜不禁懷疑一切乃因茱莉亞而起。當漢娜找到了茱莉亞的部落格後,發現茱莉亞沉迷暗網多時,並將蟄伏在暗網深處的恐怖力量帶到了現實之中,沾有嗜血意志的自拍照正威脅每一個人…… ★《與神同行》超人氣女星金香起突破演技暖心動人力作! ★「男神」鄭雨盛、「國民萌妹」金香起睽違17年再度攜手! ★《向左愛向右愛》《記憶中的美好歌聲》票房大導李翰再執導演筒! ★「小迷糊」李奎炯、鄭雨盛韓國兩大型男互飆演技! 信任 是全世界最有力的證詞 律師楊淳鎬(鄭雨盛飾)加入了一家知名的法律事務所,為一名被指控殺害雇主一家的女傭辯護,這樁謀殺案廣受媒體與社會關注,淳鎬必須贏得官司才能成為事務所合夥人。然案發現場的唯一目擊證人林智友(金香起飾)是一名自閉症少女,淳鎬必須想盡辦法讓智友敞開心房出庭作證才能贏得官司。這兩個不同世界的人漸漸成為了朋友,但在案情膠著的壓力下,他必須在有限的時間內,讓智友說出真相… 【關於電影】 金香起繼《與神同行》後演技再突破 搭檔男神鄭雨盛續17年之緣! 以賣座強片《與神同行》系列電影爆紅的「國民妹妹」金香起奪下青龍電影獎「最佳女配角獎」後,睽違17年再度與「國民暖男」鄭雨盛攜手演出催淚動人新作《證人》,而金香起在2歲時拍攝第一支廣告就是和鄭雨盛合作,讓鄭雨盛驚訝表示這是非常神奇的緣分。 金香起在6歲時從廣告界踏入影壇,超齡的演技天賦讓她獲得「天才童星」的美譽,即使與黃晸玟、宋允兒、宋仲基、朴寶英、河正宇、車太鉉、朱智勛、李政宰等影帝后級別的知名影星合作也絲毫不遜色,而她在新作《證人》中首次挑戰演出自閉症少女,金香起表示:「其實接演的時候我猶豫了很久,因為這個角色難度很高。」她擔心自己無法完美詮釋,但高難度的演技挑戰又讓她躍躍欲試,最終她決定接受挑戰。鄭雨盛則表示:「金香起對表演的專注力非常驚人,她的演技魅力自然而然就流露出來了。」導演李翰也坦言金香起在《證人》中的表演非常令人動容,有好幾場戲都讓劇組人員忍不住淚灑現場,他說:「金香起的演出非常多變,你會被她真摯的演技觸動,忍不住為她哭、為她笑。」因此在所有同輩女星中,金香起是導演選角的第一人選。 ★ 熱銷300萬冊,日本超人氣國民讀物改編! ★《神隱少女》《崖上的波妞》作畫監督x《電影版聲之形》知名編劇攜手打造溫暖新作! ★ 榮獲2019年每日映畫大賞最佳動畫片! ★ 入選2019年日本奧斯卡優秀動畫電影獎! ★ 入選2018法國安錫動畫影展競賽片! 就讀小學六年級的小織,父母不幸在車禍中喪生,由經營「春之屋」溫泉旅館的奶奶收養了她,因這場意外獲得通靈能力的她,也認識了旅館中三個心地善良卻調皮的幽靈。在旅館面臨後繼無人將被收購的困境時,年僅12歲的小織在奶奶的幫助下,展開一場成為旅館老闆娘必經的「小女將修行」之路,雖然每天都遭遇嘲笑與挫折,但天性樂觀的她勇於接受挑戰,絕不認輸!《溫泉屋小女將》將於2019年2月27日上映,更多電影資訊歡迎上官方粉絲團查詢:https://www.facebook.com/VVPfans。 索尼影業最新電影《密弑遊戲》以時下最流行的密室逃脫遊戲為主題,由《陰兒房第4章:鎖命亡靈》亞當羅勃提爾導演執導、《玩命關頭》系列億萬製片打造,並由《太空迷航》影集的泰勒羅素與《親愛的初戀》羅根米勒等明星主演,台灣將於2月27日上映。 《密弑遊戲》電影講述6名從不同意外中生還的陌生人,在努力回歸正常生活時,突然收到不明來歷的密室逃脫遊戲邀請。遊戲中總共有5大關卡:「毒火煉獄」、「冰天雪地」、「顛倒世界」、「毒氣密室」與「迷幻空間」,在不同闖關過程中,他們亦被迫面對自我最黑暗的過往瘡疤,他們也才意識到這不只是場遊戲,為求生存與贏取高達百萬美元的獎金,所有人不僅需互相幫助,還必須賭上性命互相傷害,因為最後只能有一位贏家倖存… |
取出介紹文,並清理換行等符號。
|
1 2 |
Intros = [t.find('span').text.replace('\n','').replace('\r','').replace('\xa0','').replace(' ','') for t in newMovie4] Intros |
|
1 2 3 4 5 6 7 8 9 10 |
['★奧斯卡金獎得主亞當麥凱繼《大賣空》後,攜手克里斯汀貝爾、史提夫卡爾三巨頭再度合作★「蝙蝠俠」克里斯汀貝爾再展變色龍演技,傳神詮釋史上最有權勢副總統迪克錢尼★奧斯卡最佳男配角山姆洛克威爾與克里斯汀貝爾聯袂扮老,精湛化身小布希★布萊德彼特與《月光下的藍色男孩》監製共同打造,強勢問鼎2019奧斯卡最佳影片、影帝等獎項!《為副不仁》講述美國史上最有權勢的副總統迪克錢尼(克里斯汀貝爾飾),如何從白宮幕僚逐漸爬上權力的頂峰,成為全世界最有權勢的人--美國總統小布希(山姆洛克威爾飾)的副手,以及他的政策如何重塑美國並影響至今我們身處的世界。', '★《惡女羅曼死》原著作者又一爭議話題傑作改編電影化!★殺人分屍案死者身份確認,完全沒想到,竟然就是我的好友!★現代東京版《羅生門》,懸疑曲折超越《渴望》、《聽說桐島退社了》!★新生代實力演員群,共同演繹謳歌青春電影傑作!★絢爛畫面搭配動感配樂,滿足視覺與聽覺的雙重饗宴!★藤岡靛、吉岡里帆、櫻井友紀、白石和彌等日本影視圈名人爭相力讚!話題人物慘遭殺害,連鎖效應在好友圈無限蔓延一群揮霍青春的青年男女,其中一位長相可愛貌美,猶如眾人「吉祥物」般存在、暱稱為「吉娃娃」的20歲少女,某天驚傳遭人分屍的命案,部分屍體並在東京灣尋獲。她周遭的好友們,開始聚在一起回憶青春,緬懷他們心目中的吉娃娃。大家這時才發現,根本沒人知道她的真名、境遇還有真正的個性。原來在大家對她毫無了解的情況下,她就跟眾人混在一起、談戀愛、甚至發生性關係。究竟真正的「吉娃娃」,到底是位什麼樣的女孩呢?【關於電影】《惡女羅曼死》作者話題傑作,懸疑曲折超越《聽說桐島退社了》《吉娃娃羅曼死》改編自日本知名漫畫家岡崎京子的短篇漫畫作品。曾打造《惡女羅曼死》等轟動不已作品的岡崎京子,特別擅長描繪情慾與悖德,並透過毫無忌諱的性愛場面表現人物內在。這部短篇漫畫,終於在2019年翻拍成劇情長片登上大銀幕。全片描述個性活潑好動、集萬千寵愛於一身的20歲美少女「吉娃娃」,某天竟被殘忍分屍,而她的遭遇也在朋友圈中引發連鎖效應。眾人開始回想自己與「吉娃娃」的每個相處細節,竟發現自己連她的本名、境遇與背景都不知道。也因為好友們各說各話,在不同說法中拼湊出吉娃娃的生活與背景,更讓本片頗有現代女性版《羅生門》的懸疑性,更猶如《渴望》、《聽說桐島退社了》的加乘綜合版。本片找來曾執導《裸睡美人》的二宮健擔任導演。二宮導演透露,親手拍攝《吉娃娃羅曼史》的真人電影版,一直是他給自己設立的目標,他並回憶:「初次拜讀原作,是我22歲剛從大阪到東京來的時候。那時我雖然想在東京拍攝更大規模的電影,卻諸事不順;即便想讓自己做些什麼,到頭來總是繞回原點,恰好就是那樣的時期,讓我遇到了這部作品。」他並補充:「只花34頁篇幅描繪的青春群像劇,卻帶來非常大的震撼。這群想試著跨越些什麼而掙扎的人物,逐漸跟我的自身形象交疊,以致於在看完原作的瞬間,我就決定要把這部作品給拍成電影。」值得一提的是,二宮導演的作品總有著最前衛的影像,以及動感的配樂,讓他的導演風格非常鮮明並深受好評。尤其本片的派對群戲眾多,導演這次也採用讓演員自由發揮的即興表演,再由鏡頭一一收錄,讓全片的派對、玩樂、性愛等場面顯得特別真實。本片演員也是一時之選,找來2019年新科藍絲帶獎影后門脇麥擔綱演出「美樹」這個角色,而讀完劇本的她也覺得「非常有趣,很想試試看」而馬上答應邀約。至於靈魂人物「吉娃娃」,則找來新銳女星吉田志織擔綱。她獨特又魅力十足,時而無邪、時而深沉,立體的人物塑造和強烈的存在感,讓人簡直無法相信這是她的首部主演作品。此外,本片也集結成田凌、寬一郎、村上虹郎、玉城蒂娜、栗山千明、淺野忠信等多位新銳、資深實力派演員共同演繹,聯手呈現年輕人面對愛情、金錢、嫉妒、慾望等如夢境般閃亮不已的絢爛青春世界。而全片所勾勒「青春的爆發」與「告終的覺悟」,導演也精準使用過去日本電影從未有過的影像與音樂勾勒出來,勢必滿足觀眾視覺與聽覺的雙重享受,一同進入青春大無畏的美麗與哀愁!', '★2019開春最受期待復仇爽片!冷暴力美學、血花散遍!★地表最強老爸-連恩尼遜,重拾槍火即刻開戰!復仇是人性最原始的反撲!殺我兒,我滅你全團!剷雪車司機-尼爾剛獲頒榮譽市民表揚,卻收到兒子吸毒致死的訊息,讓他生活頓時起了波瀾。他堅信兒子清白,便開始追查,赫然發現幕後有黑道組織操刀,他從朋友手中獲得黑道兇嫌名單,並依姓名順序送凶手上斷頭台。冰天雪地中,黑道們一個個死於非命,尼爾的復仇行為讓毒梟跟槍火幫派,以為是雙方在找麻煩,進而引發兩個幫派大火拼。為了幫兒子報仇,尼爾也陷入這場世紀廝殺中,雙方頓時火力全開,復仇計畫大快人心…【幕後花絮】《酷寒殺手》翻拍自爛番茄新鮮度90%超強好評《該死的順序》,導演漢斯彼得穆蘭開創新暴力美學風格,電影公司買下版權後並無改換導演,仍由漢斯繼續拍攝美語版本,融入更多美式暴力作風。導演當時會想拍這部片,是來自本身被霸凌的怨念:「我從小就喜歡報仇,只要有人欺負我,我就會反擊。」導演認為,復仇是人類非常原始的直覺,儘管沒有達到報仇目的,也能享受到樂趣。《該死的順序》當年在柏林影展首映之後,全球影評佳評如潮!帝國雜誌給予極高的讚賞,「這才是我們期待已久的復仇爽片!」知名影評網站爛番茄新鮮度近90%超強好評!國際評論對於《該死的順序》師法柯恩兄弟,也超越昆汀塔倫提諾和盧貝松的暴力美學大加讚揚!片商看中電影超強口碑便著手進行翻拍,將新暴力美學旋風帶入好萊塢;找來具有票房號召力男星-連恩尼遜擔任片中的復仇老爸。雖然連恩尼遜演出這類型的電影並不陌生,但在新片中,導演讓連恩尼遜有更多的內心戲與謀略策畫,他也不再英勇無敵,沒有特務、警察等背景,單純是一位平凡的復仇父親。在製作方面,麥可雪恩伯格曾擔任過《決殺令》製片,負責本片的暴力美學演繹,而《疾速救援》製片-麥可德雷爾,則擔綱起片中動作炫技保證,讓電影《酷寒殺手》重新定義暴力極致。', '★真人實事改編一生致力平權美國傳奇女法官成功奇蹟登上大銀幕★《愛的萬物論》金獎提名費莉絲蒂瓊斯X《以你的名字呼喚我》艾米漢默聯手主演★《彗星撞地球》票房女導演咪咪蕾德睽違大銀幕多年最新力作★為信念奮鬥不懈為歧視挺身而出繼《永不妥協》後又一激勵人心銀幕佳作★故事主角露絲拜德金斯伯格親自客串演出「如果連法律都不能一視同仁,兩性如何平權?」取材自現今美國最高法院唯二女大法官露絲拜德金斯伯格(菲莉絲蒂瓊斯飾)的真實成功故事,本片聚焦在年紀輕輕、剛踏出法學院校門的她,如何在男性至上、女性不被重視的工作環境中,力爭上游成為律師,為兩性爭取平權,成為美國史上最有影響力的法官之一,現在仍任職於最高法院大法官。', '★2019開年最爆笑噴飯喜劇,香港鬼才彭浩翔瘋狂作品,《春嬌與志明》班底火力全開,一定要你笑翻天★香港最不可思議的八婆女星大集合,為了一瓶奶!?展開瘋狂大作戰由8個閨密組成的「八婆」whatsapp群組,因彼此的恩怨,讓群組不再對話。而June也在認識了現在的老公後,漸漸疏遠其他7位閨密。她的女魔頭上司最近生了小孩,需要定時抽母奶放進冰箱。沒想到,June竟然誤把母奶加進咖啡裡,還被大老闆喝個精光,要是被發現肯定工作不保。情急之下,她只好找回很久沒聯絡的群組成員,希望在下班前,幫忙找到母奶頂替。此時,即將襲港的颱風逼近,交通大亂,八婆們能否在時間之內,完成尋奶任務呢?', '亞倫是法國出版界的風雲人物,然而時代在變,亞倫也忙於適應電子世代帶給出版業的衝擊,他不僅要學習如何發行電子書,就連讀者的消費取向也令他匪夷所思。人氣博主、暢銷部落客只要將在社群媒體發表的短文集結成冊,也能成為暢銷書?亞倫拒絕出版與他年紀相仿且合作多年的作家李奧納多的新書,他的作品寫得多半是自己的真實經驗,再將筆下人物稍加改名換姓,他的前妻、前任女友以及被影射的周遭人物深受其擾。這次的新書是李奧納多跟某個名人芝麻綠豆般的緋聞軼事,亞倫質疑他根本沒有創意以及想像力,然而出人意表的是亞倫身為名人的妻子卻認為這是李奧納多最好的作品…曾經榮獲坎城影展最佳導演、法國中生代最知名的導演奧利維耶阿薩亞斯今年入圍威尼斯影展競賽之作,這也是他與茱麗葉畢諾許第三度合作。導演精心設計的日常對話,涵蓋文化、民主、政治以及時事等多面向,幽默諷刺又饒富哲學寓意,尤其對現實世界女明星茱麗葉畢諾許的一番嘲弄,令人會心一笑。茱麗葉畢諾許與吉翁卡列精彩的演出令人驚艷。【關於電影】強勢挑戰大時代議題阿薩亞斯回歸16釐米力抗數位狂潮《非.虛構情事》講述近年討論度最高的議題之一——傳統紙本出版業與電子書的價值觀拉扯。在銳不可擋的現代數位化潮流當中,阿薩亞斯從未停止關注紙本書出版面臨到的夕陽產業議題,延續了過去作品《夏日時光》、《星光雲寂》中對於全球化、經濟、科技以及文化在時代下變遷的討論,從個人及群體角度出發,採用了輕鬆幽默卻又充滿哲學性的論調,讓觀眾能夠輕巧的進入議題核心。本片透過絕妙對話──無論是兩人世界或是團體聚會,還是身為編輯與明星、作家與政治狂熱組合的夫妻檔、偷情對象、工作夥伴──建構出不同背景的人們處於變遷的世界中,被傳統以及新潮拉扯的糾結感。另外,在片中描述面對現代化的掙扎時,阿薩亞斯的敘事角度選擇欣然理解當前數位化的崇高地位,但在技術方面卻選擇回歸以16釐米膠捲拍攝,盼望以創作初衷,在與資本主義的抗衡中找到更多討論空間。被問到劇中作家因大量採用自身故事作為創作題材而備受爭議,阿薩亞斯笑說:「我應該比他有道德一點吧!」法文片名原意為「雙面人生」,跟英文片名「非.虛構情事」交錯出真實與虛構從來就無法完全切割的深層寓意;電影中出版社提議可以找大明星茱麗葉畢諾許來為有聲書配音,以刺激銷量,飾演女主角瑟琳娜的正是茱麗葉本人,她在片中神回覆「我認識她的經紀人,或許可以關說一下」。劇中被嘲諷的茱麗葉畢諾許同時活靈活現地存在在電影裡,「故事無非就是現實生活的一面鏡子啊」。阿薩亞斯三度合作大滿貫影后全新卡司歡樂滿堂茱麗葉畢諾許的影后身影無庸置疑是片中一大亮點,《非.虛構情事》是她第三次與阿薩亞斯合作,相知多年的兩人早有絕佳默契,阿薩亞斯受訪時表示:「她的不羈、詼諧都讓我的靈感源源不絕。」並認為只有她能夠讓瑟琳娜的幽默立體化;而曾被封為法國最帥男演員的吉翁卡列則是在阿薩亞斯寫作過程中逐漸成形的想法,認為身為這一代最有代表性的男演員之一,只有他有資格撐得起這個角色的權威感,成功吸引觀眾的目光;而出身舞台劇演員及導演的文森馬格恩也自帶氣場,讓劇中金牌編輯與風流作家的對手戲,與吉翁卡列第一次合作就激盪出充滿電力的精彩火花。除了茱麗葉畢諾許與阿薩亞斯以外,其他卡司皆是首度合作,但執導過程中,阿薩亞斯忍不住盛讚演員們,「比我更清楚如何演繹出腳本中的幽默,甚至共鳴出新的層次!」', '★改編自2015年在YouTube創下逾2000萬次點閱同名恐怖短片★《愛殺瑪莉》製片群傾力打造,驚嚇程度直逼《鬼關燈》《陰兒房》!★21世紀的科技驚悚預言,直達地獄的恐怖自拍!★新世紀文明病,這次真的會送命!德國部落客茱莉亞來到美國拜訪她的姪女漢娜,卻在抵達後突然怪病纏身,臥床不起。漢娜家也開始接二連三地出現各種不尋常的超自然現象,不堪其擾的漢娜不禁懷疑一切乃因茱莉亞而起。當漢娜找到了茱莉亞的部落格後,發現茱莉亞沉迷暗網多時,並將蟄伏在暗網深處的恐怖力量帶到了現實之中,沾有嗜血意志的自拍照正威脅每一個人……', '★《與神同行》超人氣女星金香起突破演技暖心動人力作!★「男神」鄭雨盛、「國民萌妹」金香起睽違17年再度攜手!★《向左愛向右愛》《記憶中的美好歌聲》票房大導李翰再執導演筒!★「小迷糊」李奎炯、鄭雨盛韓國兩大型男互飆演技!信任是全世界最有力的證詞律師楊淳鎬(鄭雨盛飾)加入了一家知名的法律事務所,為一名被指控殺害雇主一家的女傭辯護,這樁謀殺案廣受媒體與社會關注,淳鎬必須贏得官司才能成為事務所合夥人。然案發現場的唯一目擊證人林智友(金香起飾)是一名自閉症少女,淳鎬必須想盡辦法讓智友敞開心房出庭作證才能贏得官司。這兩個不同世界的人漸漸成為了朋友,但在案情膠著的壓力下,他必須在有限的時間內,讓智友說出真相…【關於電影】金香起繼《與神同行》後演技再突破\u3000搭檔男神鄭雨盛續17年之緣!以賣座強片《與神同行》系列電影爆紅的「國民妹妹」金香起奪下青龍電影獎「最佳女配角獎」後,睽違17年再度與「國民暖男」鄭雨盛攜手演出催淚動人新作《證人》,而金香起在2歲時拍攝第一支廣告就是和鄭雨盛合作,讓鄭雨盛驚訝表示這是非常神奇的緣分。金香起在6歲時從廣告界踏入影壇,超齡的演技天賦讓她獲得「天才童星」的美譽,即使與黃晸玟、宋允兒、宋仲基、朴寶英、河正宇、車太鉉、朱智勛、李政宰等影帝后級別的知名影星合作也絲毫不遜色,而她在新作《證人》中首次挑戰演出自閉症少女,金香起表示:「其實接演的時候我猶豫了很久,因為這個角色難度很高。」她擔心自己無法完美詮釋,但高難度的演技挑戰又讓她躍躍欲試,最終她決定接受挑戰。鄭雨盛則表示:「金香起對表演的專注力非常驚人,她的演技魅力自然而然就流露出來了。」導演李翰也坦言金香起在《證人》中的表演非常令人動容,有好幾場戲都讓劇組人員忍不住淚灑現場,他說:「金香起的演出非常多變,你會被她真摯的演技觸動,忍不住為她哭、為她笑。」因此在所有同輩女星中,金香起是導演選角的第一人選。', '★熱銷300萬冊,日本超人氣國民讀物改編!★《神隱少女》《崖上的波妞》作畫監督x《電影版聲之形》知名編劇攜手打造溫暖新作!★榮獲2019年每日映畫大賞最佳動畫片!★入選2019年日本奧斯卡優秀動畫電影獎!★入選2018法國安錫動畫影展競賽片!就讀小學六年級的小織,父母不幸在車禍中喪生,由經營「春之屋」溫泉旅館的奶奶收養了她,因這場意外獲得通靈能力的她,也認識了旅館中三個心地善良卻調皮的幽靈。在旅館面臨後繼無人將被收購的困境時,年僅12歲的小織在奶奶的幫助下,展開一場成為旅館老闆娘必經的「小女將修行」之路,雖然每天都遭遇嘲笑與挫折,但天性樂觀的她勇於接受挑戰,絕不認輸!《溫泉屋小女將》將於2019年2月27日上映,更多電影資訊歡迎上官方粉絲團查詢:https://www.facebook.com/VVPfans。', '索尼影業最新電影《密弑遊戲》以時下最流行的密室逃脫遊戲為主題,由《陰兒房第4章:鎖命亡靈》亞當羅勃提爾導演執導、《玩命關頭》系列億萬製片打造,並由《太空迷航》影集的泰勒羅素與《親愛的初戀》羅根米勒等明星主演,台灣將於2月27日上映。《密弑遊戲》電影講述6名從不同意外中生還的陌生人,在努力回歸正常生活時,突然收到不明來歷的密室逃脫遊戲邀請。遊戲中總共有5大關卡:「毒火煉獄」、「冰天雪地」、「顛倒世界」、「毒氣密室」與「迷幻空間」,在不同闖關過程中,他們亦被迫面對自我最黑暗的過往瘡疤,他們也才意識到這不只是場遊戲,為求生存與贏取高達百萬美元的獎金,所有人不僅需互相幫助,還必須賭上性命互相傷害,因為最後只能有一位贏家倖存…'] |
檢查NameCHs, NameENs, Intros, links陣列的長度是否相同(結果皆為10)。
|
1 2 3 4 |
len(NameCHs) len(NameENs) len(Intros) len(links) |
(3) 將以上欄位合併成data frame
|
1 2 3 4 5 6 7 8 |
df = pd.DataFrame( { 'Name':NameCHs, 'EnName':NameENs, 'Intro': Intros, 'Trailer': links }) df |

由於以上只是「本週新片」中的其中一個分頁的電影爬蟲結果,如果想要快速爬取其他分頁的資訊,可將電影爬蟲寫成一個function。
(4) 將電影爬網規則寫成function
define 一個名為「yahooMovieParser」的函數,並以url為投入參數。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
# create function def yahooMovieParser(url): r = requests.get(url) web_content = r.text soup = BeautifulSoup(web_content,'lxml') # 中英文片名 newMovie2 = soup.find_all('div', class_ = "release_movie_name") NameCHs = [t.find('a', class_='gabtn').text.replace('\n','').replace(' ','') for t in newMovie2] NameENs = [t.find('div', class_='en').find('a').text.replace('\n','').replace(' ','') for t in newMovie2] # 預告片 newMovie3 = soup.find_all('div',class_="release_btn color_btnbox") links = [t.find('a',class_="btn_s_vedio gabtn")['href'] for t in newMovie3] # 電影介紹 newMovie4 = soup.find_all('div',class_="release_text") Intros = [t.find('span').text.replace('\n','').replace('\r','').replace('\xa0','').replace(' ','') for t in newMovie4] #合併成data frame df = pd.DataFrame( { 'Name':NameCHs, 'EnName':NameENs, 'Intro': Intros, 'Trailer': links }) return df |
執行單一URL: 手動指定url並投入函式。
|
1 2 3 |
url = "https://movies.yahoo.com.tw/movie_thisweek.html" df1 = yahooMovieParser(url) df1 |
執行多個URLs
將多個 url包成一個陣列 list 使用迴圈執行並回傳一個data frame
|
1 2 3 4 5 6 7 8 9 10 11 |
urlList = ['https://movies.yahoo.com.tw/movie_thisweek.html','https://movies.yahoo.com.tw/movie_thisweek.html?page=2'] MovieInfo = None for u in urlList: d1 = yahooMovieParser(u) if MovieInfo is None: MovieInfo = d1 else: MovieInfo = MovieInfo.append(d1,ignore_index=True) MovieInfo |

但由於分頁的URLs都還是人工判斷,如果可以用程式規則判斷並蒐集所有分頁,將省去更多工。
(5) 自動判斷分頁資訊,蒐集urlList
首先,一樣先找到分頁資訊的區塊,並檢視其HTML結構。發現分頁資訊會被包含在class = ‘page_numbox’的div物件中。
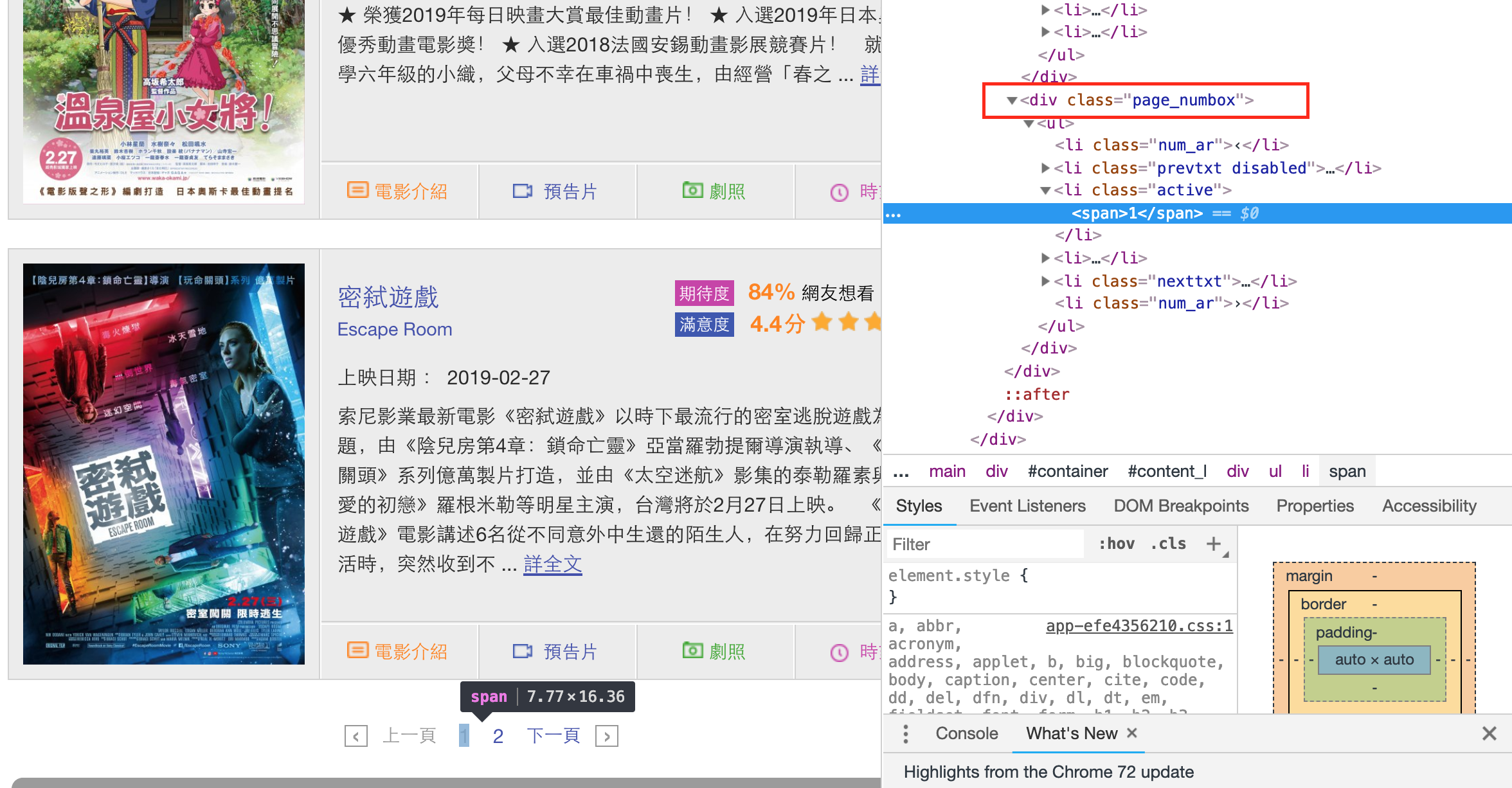
|
1 2 3 4 5 6 |
url = "https://movies.yahoo.com.tw/movie_thisweek.html" r = requests.get(url) web_content = r.text soup = BeautifulSoup(web_content,'lxml') pageInfo = soup.find('div', class_='page_numbox') pageInfo |
撰寫一個萃取分頁URL資訊的函式。
- 將分頁資訊的每個 元素中的連結取出,假設沒有連結資訊,則回傳None。
|
1 2 3 4 5 6 7 8 9 10 |
def getNext(url): r = requests.get(url) web_content = r.text soup = BeautifulSoup(web_content,'lxml') pageInfo = soup.find('div', class_='page_numbox') tagA = pageInfo.find('li', class_="nexttxt").find('a') if tagA: return tagA['href'] else: return None |
測試函式getNext()執行一次的結果。
|
1 2 3 |
url = "https://movies.yahoo.com.tw/movie_thisweek.html" url2 = getNext(url) url2 |
|
1 |
'http://movies.yahoo.com.tw/movie_thisweek.html?page=2' |
使用while迴圈反覆執行,直到getNext()回傳None。
|
1 2 3 4 5 6 |
url = 'http://movies.yahoo.com.tw/movie_thisweek.html' urlList = [] while url: urlList.append(url) url = getNext(url) |
檢視所有的分頁連結 (當分頁數很多時特別有效)
|
1 |
urlList |
|
1 2 |
['http://movies.yahoo.com.tw/movie_thisweek.html', 'http://movies.yahoo.com.tw/movie_thisweek.html?page=2'] |
綜合(1) ~ (5)電影爬蟲程式碼,自動化執行url List蒐集並爬取每個分頁下的最新電影資訊的程式碼如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
url = 'http://movies.yahoo.com.tw/movie_thisweek.html' urlList = [] while url: urlList.append(url) url = getNext(url) MovieInfo = None for u in urlList: d1 = yahooMovieParser(u) if MovieInfo is None: MovieInfo = d1 else: MovieInfo = MovieInfo.append(d1,ignore_index=True) MovieInfo |
更多Python網路爬蟲學習筆記:
網路爬蟲 Web Crawler | 資料不求人 基礎篇 | using Python BeautifulSoup