



本篇學習筆記將要示範如何使用 Python 來執行 網路爬蟲 web crawler 與 basic text mining ,並以爬取Google News 的「健康」類別新聞為例。筆記包含以下部分:(1) 爬取新聞標題 (2) 爬取新聞連結 (3) 新聞文章斷詞(jieba)與字詞頻率分析(文字雲) 。
網路爬蟲 web crawler
載入套件、指定目標URL、並解析HTML
|
1 2 3 4 5 6 7 8 9 |
import requests from bs4 import BeautifulSoup import pandas as pd url = 'https://news.google.com/topics/CAAqJQgKIh9DQkFTRVFvSUwyMHZNR3QwTlRFU0JYcG9MVlJYS0FBUAE?hl=zh-TW&gl=TW&ceid=TW%3Azh-Hant' r = requests.get(url) web_content = r.text soup = BeautifulSoup(web_content,'lxml') |
1. 找出所有新聞的標題
先檢視新聞標題在HTML的規則。
可以發現:
- 每個文章小卡都是包覆在class = ‘xrnccd’的div物件中
- 整個文章小卡點擊區塊連結: class = “VDXfz”
- 文章小卡中的標題則是包覆在class為’mEaVNd’的div物件中
- 標題文字則是在標籤中
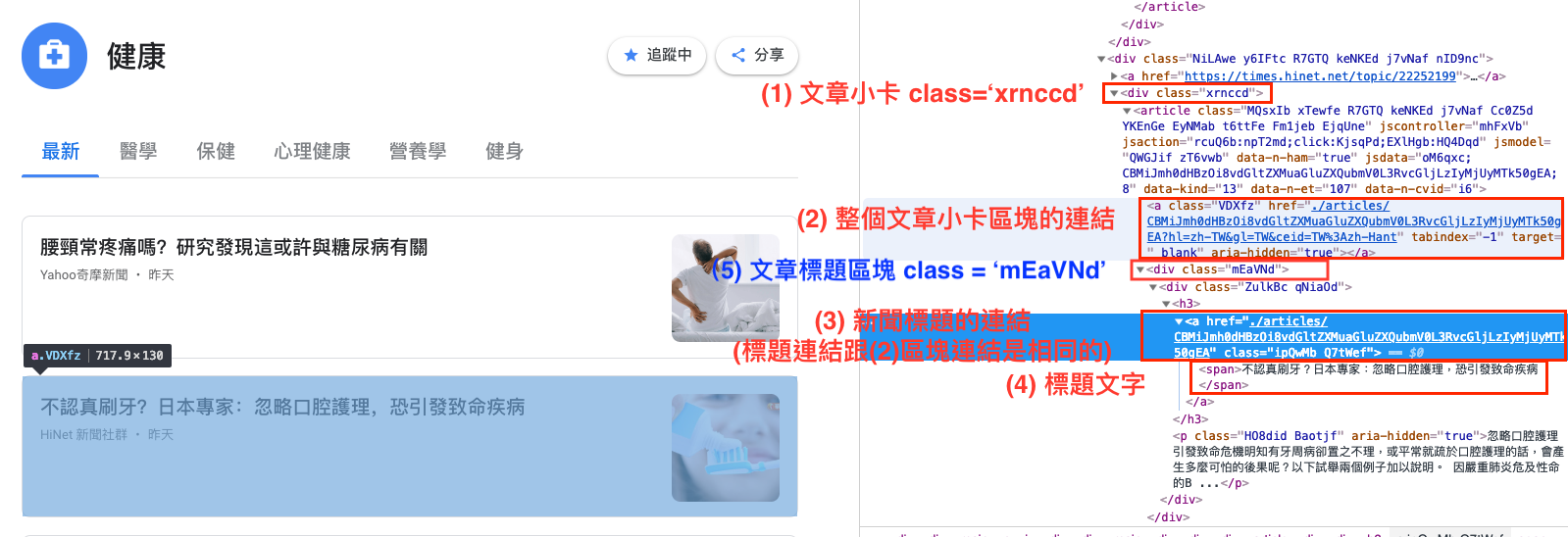
找出所有文章小卡中class = ‘mEaVNd’的「標題區塊」的元素並儲存為一個list (named title)
list中每一個「標題區塊」元素是以逗號做區隔
|
1 2 |
title = soup.find_all('div', class_='mEaVNd') print(title) |

再從「標題區塊」list中,找出每個元素的標籤,並萃取出標題文字
|
1 2 |
titles = [t.find('span').text for t in title] titles |
|
1 2 3 4 5 6 |
['腰頸常疼痛嗎?研究發現這或許與糖尿病有關', '不認真刷牙?日本專家:忽略口腔護理,恐引發致命疾病', '不舉、憂鬱、沒精神,恐怕是「男性更年期」來報到?醫生:出現這8種症狀,趕快去檢查', '一餐吃十幾塊蘿蔔糕,血糖就意外飆高…營養師4大建議,吃東西真的要謹慎啊!', '男性更年期同樣讓人崩潰!50歲上下都得注意,醫師3招緩解情緒不穩、早洩問題', '原來做巧克力餅乾這麼簡單!微波爐5分鐘搞定,颱風天在家做做看吧'] |
2. 找出新聞標題所對應的資料來源links
新聞連結的取得是比較tricky的部分,因為google news網頁中html 標籤中的連結是經過另外轉換的,所以需要request.get()另外取得轉換後的真實文章URL。
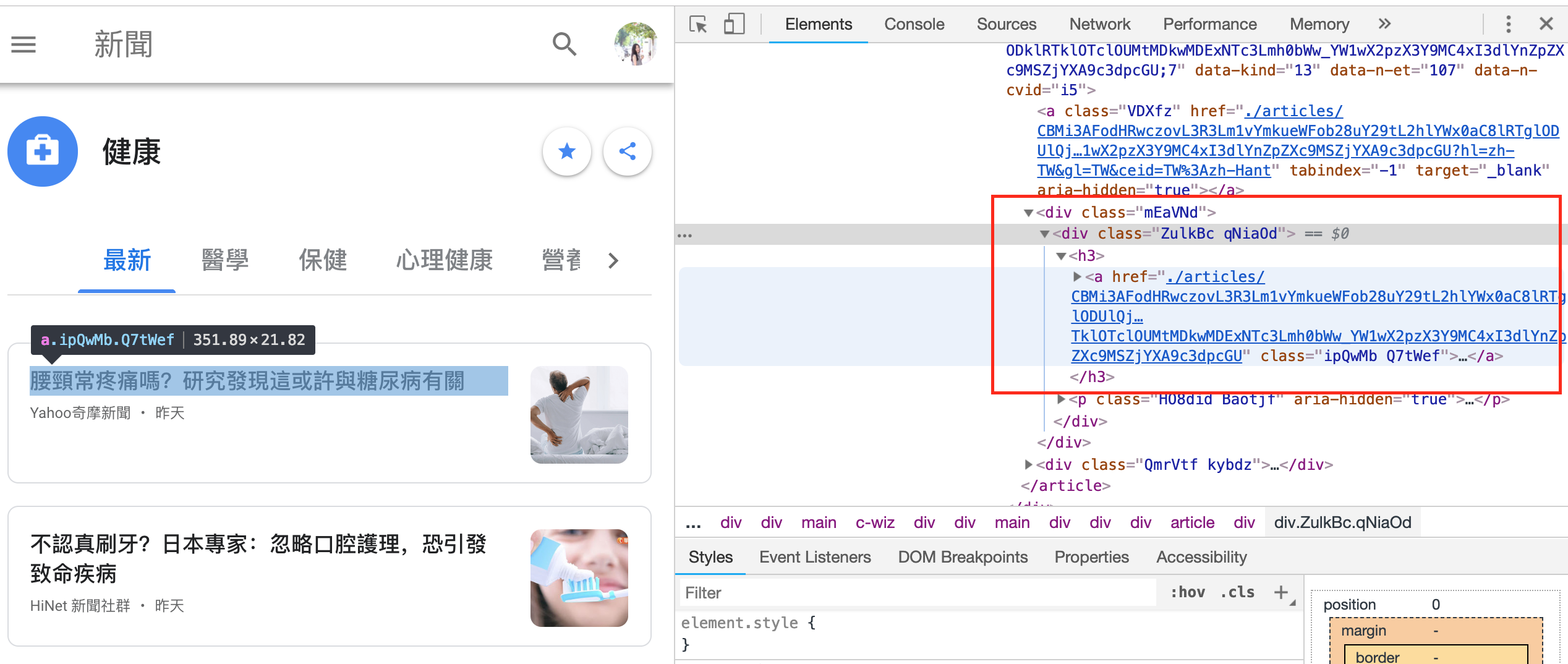
取得新聞文章真實URL:
|
1 2 |
newUrls = [requests.get(t.find('a')['href'].replace('.','https://news.google.com',1)).url for t in title] newUrls |
|
1 2 3 4 5 6 |
['https://tw.news.yahoo.com/%E8%85%B0%E9%A0%B8%E5%B8%B8%E7%96%BC%E7%97%9B%E5%97%8E-%E7%A0%94%E7%A9%B6%E7%99%BC%E7%8F%BE%E9%80%99%E6%88%96%E8%A8%B1%E8%88%87%E7%B3%96%E5%B0%BF%E7%97%85%E6%9C%89%E9%97%9C-090011577.html', 'https://n.yam.com/Article/20190301775078', 'https://www.storm.mg/lifestyle/469667', 'https://www.storm.mg/lifestyle/219203', 'https://www.storm.mg/lifestyle/294616', 'https://www.storm.mg/lifestyle/110852'] |
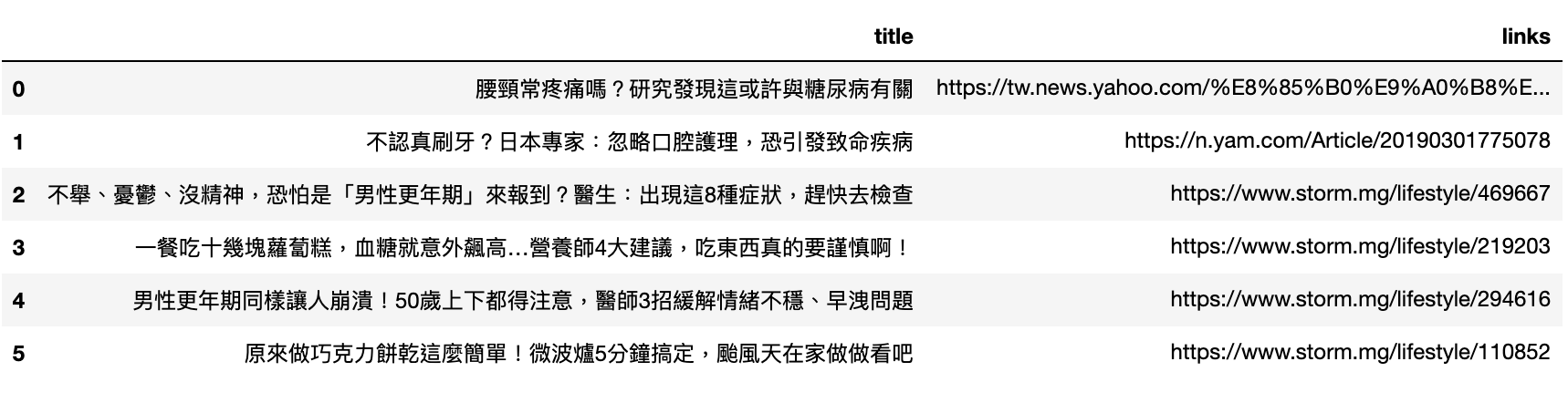
3. 將標題與連結合併成data frame
這樣就能新聞標題和真實出處URL做一個簡易的資訊表格整理
|
1 2 3 4 5 6 7 |
df = pd.DataFrame( { 'title': titles, 'links': newUrls }) df |
其他爬蟲結果輸出可以參考「網路爬蟲 Web Crawler | 資料不求人 基礎篇 | using Python BeautifulSoup」。
Text mining 簡易字頻分析 (文字雲 word cloud)
4. 使用jieba套件,進行文章中文斷詞分析
先使用某一篇文章內文為範例,我們使用剛剛新聞清單的第一個連結去得到文章內容。並以該文章內容進行字頻分析(文字雲)。
|
1 2 3 4 5 |
url = df['links'][0] print(url) r = requests.get(url) web_content = r.text soup = BeautifulSoup(web_content,'lxml') |
看一下文章段落在HTML的規則:
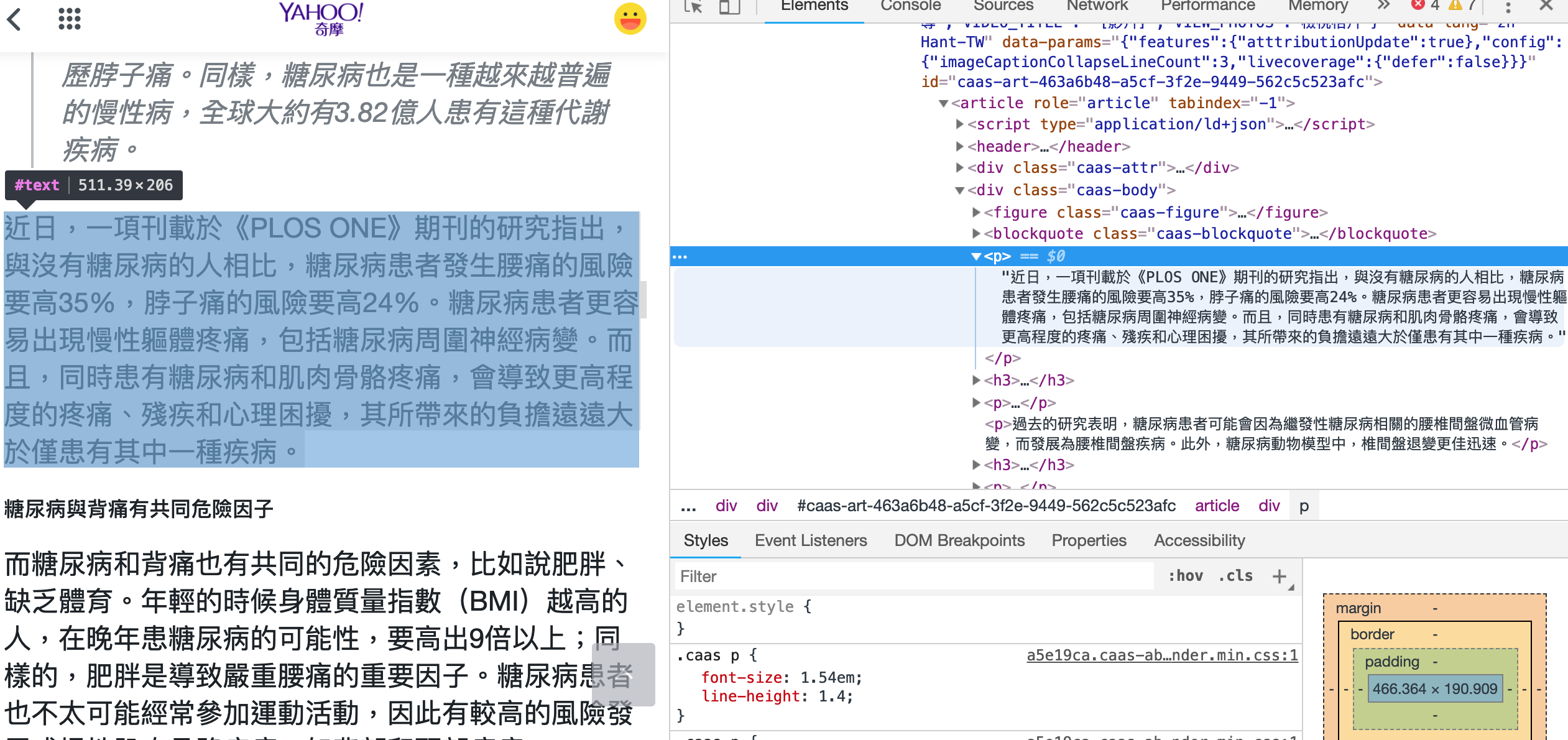
擷取文章內容如下:
|
1 2 |
articleContent = soup.find_all('p') articleContent |
|
1 2 3 4 5 6 7 8 9 10 11 |
[ 腰頸疼痛是常見的肌肉骨骼疾病,根據統計,大約80%的成年人會經歷腰痛,47%的人會經歷脖子痛。同樣,糖尿病也是一種越來越普遍的慢性病,全球大約有3.82億人患有這種代謝疾病。 ,近日,一項刊載於《PLOS ONE》期刊的研究指出,與沒有糖尿病的人相比,糖尿病患者發生腰痛的風險要高35%,脖子痛的風險要高24%。糖尿病患者更容易出現慢性軀體疼痛,包括糖尿病周圍神經病變。而且,同時患有糖尿病和肌肉骨骼疼痛,會導致更高程度的疼痛、殘疾和心理困擾,其所帶來的負擔遠遠大於僅患有其中一種疾病。 ,而糖尿病和背痛也有共同的危險因素,比如說肥胖、缺乏體育。年輕的時候身體質量指數(BMI)越高的人,在晚年患糖尿病的可能性,要高出9倍以上;同樣的,肥胖是導致嚴重腰痛的重要因子。糖尿病患者也不太可能經常參加運動活動,因此有較高的風險發展成慢性肌肉骨骼疾病,如背部和頸部疼痛。 ,過去的研究表明,糖尿病患者可能會因為繼發性糖尿病相關的腰椎間盤微血管病變,而發展為腰椎間盤疾病。此外,糖尿病動物模型中,椎間盤退變更佳迅速。 ,該論文的作者Manuela Ferreira副教授說,目前還沒有足夠的證據證明糖尿病與腰頸疼痛之間存在因果關係,但這種積極聯繫值得進一步調查和研究。論文還建議醫護人員,應該考慮對長期頸痛或腰痛患者進行糖尿病篩查。 ,「越來越多的人同時受到頸背疼痛和糖尿病的折磨,」論文共同作者Paulo Ferreira說道,「所以,值得投入更多的資源來研究它們之間的相互關係。改變糖尿病的治療干預措施可,或許以減少背痛的發病率,反之亦然。」 ,期刊小檔案:《PLOS ONE》為一份同行評審的開放獲取科學期刊,由公共科學圖書館自2006年發行,為全世界文章刊載數量最多的期刊,所刊載的文章包含科學及醫學各領域的基礎研究。 , , 文/林以璿 圖/許嘉真 ] |
將所有
中的text取出並放進list。|
1 2 3 4 |
# 將所有tag p中的text取出並放進list。 article = [] for p in articleContent: article.append(p.text) |
將list中的text元素join合併成一個字串,並以特殊字元’\n’來間隔 (主要是印出好看用)
|
1 2 |
articleAll = '\n'.join(article) print(articleAll) |
|
1 2 3 4 5 6 7 8 9 |
腰頸疼痛是常見的肌肉骨骼疾病,根據統計,大約80%的成年人會經歷腰痛,47%的人會經歷脖子痛。同樣,糖尿病也是一種越來越普遍的慢性病,全球大約有3.82億人患有這種代謝疾病。 近日,一項刊載於《PLOS ONE》期刊的研究指出,與沒有糖尿病的人相比,糖尿病患者發生腰痛的風險要高35%,脖子痛的風險要高24%。糖尿病患者更容易出現慢性軀體疼痛,包括糖尿病周圍神經病變。而且,同時患有糖尿病和肌肉骨骼疼痛,會導致更高程度的疼痛、殘疾和心理困擾,其所帶來的負擔遠遠大於僅患有其中一種疾病。 而糖尿病和背痛也有共同的危險因素,比如說肥胖、缺乏體育。年輕的時候身體質量指數(BMI)越高的人,在晚年患糖尿病的可能性,要高出9倍以上;同樣的,肥胖是導致嚴重腰痛的重要因子。糖尿病患者也不太可能經常參加運動活動,因此有較高的風險發展成慢性肌肉骨骼疾病,如背部和頸部疼痛。 過去的研究表明,糖尿病患者可能會因為繼發性糖尿病相關的腰椎間盤微血管病變,而發展為腰椎間盤疾病。此外,糖尿病動物模型中,椎間盤退變更佳迅速。 該論文的作者Manuela Ferreira副教授說,目前還沒有足夠的證據證明糖尿病與腰頸疼痛之間存在因果關係,但這種積極聯繫值得進一步調查和研究。論文還建議醫護人員,應該考慮對長期頸痛或腰痛患者進行糖尿病篩查。 「越來越多的人同時受到頸背疼痛和糖尿病的折磨,」論文共同作者Paulo Ferreira說道,「所以,值得投入更多的資源來研究它們之間的相互關係。改變糖尿病的治療干預措施可,或許以減少背痛的發病率,反之亦然。」 參考資料:Study links diabetes and back pain 期刊小檔案:《PLOS ONE》為一份同行評審的開放獲取科學期刊,由公共科學圖書館自2006年發行,為全世界文章刊載數量最多的期刊,所刊載的文章包含科學及醫學各領域的基礎研究。 更多Heho健康網文章糖友肺炎風險高2.8倍 醫:加打肺炎鏈球菌疫苗保健康讓其他細胞分泌胰島素 動物實驗逆轉糖尿病! |
載入斷詞分析的套件
|
1 2 |
import jieba import nltk |
指定字典(使用預設字典)
|
1 |
jieba.load_userdict('/user_dict.txt') # 輸入自己字典的路徑 |
移除標點符號 punctuation removal
|
1 2 |
d = c.replace('[^\w\s]','').replace('/',"").replace('《','').replace('》','').replace(',','').replace('。','').replace('「','').replace('」','').replace('(','').replace(')','').replace('!','').replace('?','').replace('、','').replace('▲','').replace('…','').replace(':','') print(d) |
|
1 2 3 4 5 6 7 8 9 10 11 |
腰頸疼痛是常見的肌肉骨骼疾病根據統計大約80%的成年人會經歷腰痛47%的人會經歷脖子痛同樣糖尿病也是一種越來越普遍的慢性病全球大約有3.82億人患有這種代謝疾病 近日一項刊載於PLOS ONE期刊的研究指出與沒有糖尿病的人相比糖尿病患者發生腰痛的風險要高35%脖子痛的風險要高24%糖尿病患者更容易出現慢性軀體疼痛包括糖尿病周圍神經病變而且同時患有糖尿病和肌肉骨骼疼痛會導致更高程度的疼痛殘疾和心理困擾其所帶來的負擔遠遠大於僅患有其中一種疾病 而糖尿病和背痛也有共同的危險因素比如說肥胖缺乏體育年輕的時候身體質量指數BMI越高的人在晚年患糖尿病的可能性要高出9倍以上;同樣的肥胖是導致嚴重腰痛的重要因子糖尿病患者也不太可能經常參加運動活動因此有較高的風險發展成慢性肌肉骨骼疾病如背部和頸部疼痛 過去的研究表明糖尿病患者可能會因為繼發性糖尿病相關的腰椎間盤微血管病變而發展為腰椎間盤疾病此外糖尿病動物模型中椎間盤退變更佳迅速 該論文的作者Manuela Ferreira副教授說目前還沒有足夠的證據證明糖尿病與腰頸疼痛之間存在因果關係但這種積極聯繫值得進一步調查和研究論文還建議醫護人員應該考慮對長期頸痛或腰痛患者進行糖尿病篩查 越來越多的人同時受到頸背疼痛和糖尿病的折磨論文共同作者Paulo Ferreira說道所以值得投入更多的資源來研究它們之間的相互關係改變糖尿病的治療干預措施可或許以減少背痛的發病率反之亦然 參考資料Study links diabetes and back pain 期刊小檔案PLOS ONE為一份同行評審的開放獲取科學期刊由公共科學圖書館自2006年發行為全世界文章刊載數量最多的期刊所刊載的文章包含科學及醫學各領域的基礎研究 更多Heho健康網文章糖友肺炎風險高2.8倍 醫加打肺炎鏈球菌疫苗保健康讓其他細胞分泌胰島素 動物實驗逆轉糖尿病 文林以璿 圖許嘉真 |
避免過多的文字log訊息出現
|
1 |
jieba.setLogLevel(20) |
分別使用不同斷詞模式
|
1 2 3 4 5 6 7 8 9 10 11 |
Sentence = jieba.cut(d, cut_all=True) print('全模式'+": " + "/ ".join(Sentence) + '\n') Sentence = jieba.cut(d, cut_all=False) print('精確模式'+": " + "/ ".join(Sentence)+ '\n') Sentence = jieba.cut(d) print('Default為精確模式'+": " + "/ ".join(Sentence)+ '\n') Sentence = jieba.cut_for_search(d) print('搜索引擎模式'+": " + "/ ".join(Sentence)+ '\n') |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
全模式: 腰/ 頸/ 疼痛/ 是/ 常/ 見/ 的/ 肌肉/ 骨骼/ 疾病/ 病根/ 據/ 統/ 計/ 大/ 約/ 80/ / 的/ 成年/ 成年人/ 會/ 經/ 歷/ 腰痛/ 47/ / 的/ 人/ 會/ 經/ 歷/ 脖子/ 痛/ 同/ 樣/ 糖尿/ 糖尿病/ 也/ 是/ 一/ 種/ 越/ 來/ 越/ 普遍/ 的/ 慢性/ 慢性病/ 性病/ / / / 全球/ 大/ 約/ 有/ 3/ 82/ 億/ 人/ 患有/ 這/ 種/ 代/ 謝/ 疾病/ / 近日/ 一/ 項/ 刊/ 載/ 於/ PLOS/ ONE/ 期刊/ 的/ 研究/ 指出/ 與/ 沒/ 有/ 糖尿/ 糖尿病/ 的/ 人/ 相比/ 糖尿/ 糖尿病/ 病患/ 病患者/ 患者/ 發/ 生/ 腰痛/ 的/ 風/ 險/ 要/ 高/ 35/ / 脖子/ 痛/ 的/ 風/ 險/ 要/ 高/ 24/ / 糖尿/ 糖尿病/ 病患/ 病患者/ 患者/ 更/ 容易/ 出/ 現/ 慢性/ 軀/ 體/ 疼痛/ 包括/ 糖尿/ 糖尿病/ 周/ 圍/ 神/ 經/ 病/ 變/ 而且/ 同/ 時/ 患有/ 糖尿/ 糖尿病/ 和/ 肌肉/ 骨骼/ 疼痛/ 會/ 導/ 致/ 更/ 高程/ 程度/ 的/ 疼痛/ 殘/ 疾/ 和/ 心理/ 困/ 擾/ 其/ 所/ 帶/ 來/ 的/ 負/ 擔/ 遠/ 遠/ 大/ 於/ 僅/ 患有/ 其中/ 一/ 種/ 疾病/ / 而/ 糖尿/ 糖尿病/ 和/ 背痛/ 也/ 有/ 共同/ 的/ 危/ 險/ 因素/ 比如/ 說/ 肥胖/ 缺乏/ 體/ 育/ 年/ 輕/ 的/ 時/ 候/ 身/ 體/ 質/ 量/ 指/ 數/ BMI/ 越/ 高/ 的/ 人/ 在/ 晚年/ 患/ 糖尿/ 糖尿病/ 的/ 可能/ 可能性/ 要/ 高出/ 9/ 倍/ 以上/ / / 同/ 樣/ 的/ 肥胖/ 是/ 導/ 致/ 嚴/ 重/ 腰痛/ 的/ 重要/ 因子/ 糖尿/ 糖尿病/ 病患/ 病患者/ 患者/ 也/ 不太可能/ 可能/ 經/ 常/ 參/ 加/ 運/ 動/ 活/ 動/ 因此/ 有/ 較/ 高/ 的/ 風/ 險/ 發/ 展/ 成/ 慢性/ 肌肉/ 骨骼/ 疾病/ 如/ 背部/ 和/ 頸/ 部/ 疼痛/ / 過/ 去/ 的/ 研究/ 表明/ 糖尿/ 糖尿病/ 病患/ 病患者/ 患者/ 可能/ 會/ 因/ 為/ 繼/ 發/ 性/ 糖尿/ 糖尿病/ 相/ 關/ 的/ 腰椎/ 間/ 盤/ 微血管/ 血管/ 血管病/ 變/ 而/ 發/ 展/ 為/ 腰椎/ 間/ 盤/ 疾病/ 此外/ 糖尿/ 糖尿病/ 動/ 物/ 模型/ 中/ 椎/ 間/ 盤/ 退/ 變/ 更佳/ 迅速/ / 該/ 論/ 文/ 的/ 作者/ Manuela/ Ferreira/ 副教授/ 教授/ 說/ 目前/ 還/ 沒/ 有/ 足/ 夠/ 的/ 證/ 據/ 證/ 明/ 糖尿/ 糖尿病/ 與/ 腰/ 頸/ 疼痛/ 之/ 間/ 存在/ 因果/ 關/ 係/ 但/ 這/ 種/ 積/ 極/ 聯/ 繫/ 值得/ 進/ 一步/ 調/ 查/ 和/ 研究/ 論/ 文/ 還/ 建/ 議/ 醫/ 護/ 人/ 員/ 應/ 該/ 考/ 慮/ 對/ 長/ 期/ 頸/ 痛/ 或/ 腰痛/ 患者/ 進/ 行/ 糖尿/ 糖尿病/ 篩/ 查/ / 越/ 來/ 越多/ 的/ 人/ 同/ 時/ 受到/ 頸/ 背/ 疼痛/ 和/ 糖尿/ 糖尿病/ 的/ 折磨/ 論/ 文/ 共同/ 作者/ Paulo/ Ferreira/ 說/ 道/ 所以/ 值得/ 投入/ 更多/ 的/ 資/ 源/ 來/ 研究/ 它/ 們/ 之/ 間/ 的/ 相互/ 關/ 係/ 改/ 變/ 糖尿/ 糖尿病/ 的/ 治療/ 干/ 預/ 措施/ 可/ 或/ 許/ 以/ 減/ 少背/ 背痛/ 的/ 發/ 病/ 率/ 反之/ 反之亦然/ 亦然/ / 參/ 考/ 資/ 料/ Study/ links/ diabetes/ and/ back/ pain / 期刊/ 小/ 檔/ 案/ PLOS/ ONE/ 為/ 一份/ 同行/ 評/ 審/ 的/ 開/ 放/ 獲/ 取/ 科/ 學/ 期刊/ 由/ 公共/ 科/ 學/ 圖/ 書/ 館/ 自/ 2006/ 年/ 發/ 行/ 為/ 全世界/ 世界/ 文章/ 刊/ 載/ 數/ 量/ 最多/ 的/ 期刊/ 所/ 刊/ 載/ 的/ 文章/ 包含/ 科/ 學/ 及/ 醫/ 學/ 各/ 領/ 域/ 的/ 基/ 礎/ 研究/ / 更多/ Heho/ 健康/ 網/ 文章/ 糖/ 友/ 肺炎/ 風/ 險/ 高/ 2/ 8/ 倍/ / / 醫/ 加打/ 肺炎/ 鏈/ 球菌/ 疫苗/ 保健/ 健康/ 讓/ 其他/ 細/ 胞/ 分泌/ 胰/ 島/ 素/ / / 動/ 物/ 實/ 驗/ 逆/ 轉/ 糖尿/ 糖尿病/ / 文林/ 以/ 璿/ / / 圖/ 許/ 嘉/ 真 精確模式: 腰頸/ 疼痛/ 是/ 常見/ 的/ 肌肉/ 骨骼/ 疾病/ 根據/ 統計大約/ 80%/ 的/ 成年人/ 會經歷/ 腰痛/ 47%/ 的/ 人會/ 經歷/ 脖子/ 痛同樣/ 糖尿病/ 也/ 是/ 一種/ 越來/ 越/ 普遍/ 的/ 慢性病/ / / 全球/ 大約/ 有/ 3.82/ 億人/ 患有/ 這種/ 代謝/ 疾病/ / 近日/ 一項/ 刊載/ 於/ PLOS/ / ONE/ 期刊/ 的/ 研究/ 指出/ 與/ 沒/ 有/ 糖尿病/ 的/ 人/ 相比/ 糖尿病/ 患者/ 發生/ 腰痛/ 的/ 風險/ 要/ 高/ 35%/ 脖子/ 痛/ 的/ 風險/ 要/ 高/ 24%/ 糖尿病/ 患者/ 更/ 容易/ 出現/ 慢性/ 軀體/ 疼痛/ 包括/ 糖尿病/ 周圍/ 神經/ 病變/ 而且/ 同時/ 患有/ 糖尿病/ 和/ 肌肉/ 骨骼/ 疼痛/ 會導致/ 更/ 高/ 程度/ 的/ 疼痛/ 殘疾/ 和/ 心理/ 困擾/ 其/ 所/ 帶/ 來/ 的/ 負擔/ 遠遠大/ 於僅/ 患有/ 其中/ 一種/ 疾病/ / 而/ 糖尿病/ 和/ 背痛/ 也/ 有/ 共同/ 的/ 危險/ 因素/ 比如/ 說/ 肥胖/ 缺乏/ 體育/ 年/ 輕/ 的/ 時候/ 身體/ 質量/ 指數/ BMI/ 越高/ 的/ 人/ 在/ 晚年/ 患/ 糖尿病/ 的/ 可能性/ 要/ 高出/ 9/ 倍/ 以上/ ;/ 同樣/ 的/ 肥胖/ 是/ 導致/ 嚴重/ 腰痛/ 的/ 重要/ 因子/ 糖尿病/ 患者/ 也/ 不太可能/ 經常/ 參加/ 運動/ 活動/ 因此/ 有/ 較/ 高/ 的/ 風險/ 發展/ 成/ 慢性/ 肌肉/ 骨骼/ 疾病/ 如/ 背部/ 和/ 頸部/ 疼痛/ / 過去/ 的/ 研究/ 表明/ 糖尿病/ 患者/ 可能/ 會/ 因為/ 繼發性/ 糖尿病/ 相關/ 的/ 腰椎/ 間盤/ 微血管/ 病變/ 而/ 發展/ 為/ 腰椎/ 間盤/ 疾病/ 此外/ 糖尿病/ 動物/ 模型/ 中椎間/ 盤/ 退變/ 更佳/ 迅速/ / 該論文/ 的/ 作者/ Manuela/ / Ferreira/ 副教授/ 說/ 目前/ 還沒有/ 足夠/ 的/ 證據/ 證明/ 糖尿病/ 與/ 腰/ 頸/ 疼痛/ 之間/ 存在/ 因果/ 關/ 係/ 但/ 這種/ 積極/ 聯/ 繫/ 值得/ 進/ 一步/ 調查/ 和/ 研究/ 論文/ 還建議/ 醫護/ 人員應/ 該/ 考慮/ 對長/ 期頸痛/ 或/ 腰痛/ 患者/ 進行/ 糖尿病/ 篩查/ / 越來/ 越/ 多/ 的/ 人/ 同時/ 受到/ 頸/ 背/ 疼痛/ 和/ 糖尿病/ 的/ 折磨/ 論文/ 共同/ 作者/ Paulo/ / Ferreira/ 說道/ 所以/ 值得/ 投入/ 更/ 多/ 的/ 資源/ 來/ 研究/ 它們/ 之間/ 的/ 相互/ 關/ 係/ 改變/ 糖尿病/ 的/ 治療/ 干預/ 措施/ 可/ 或/ 許以/ 減少/ 背痛/ 的/ 發病率/ 反之亦然/ / 參考/ 資料/ Study/ / links/ / diabetes/ / and/ / back/ / pain/ / 期刊/ 小檔案/ PLOS/ / ONE/ 為/ 一份/ 同行/ 評審/ 的/ 開放/ 獲取/ 科學/ 期刊/ 由/ 公共/ 科學/ 圖書館/ 自/ 2006/ 年/ 發行/ 為/ 全世界/ 文章/ 刊載/ 數量/ 最/ 多/ 的/ 期刊/ 所刊/ 載/ 的/ 文章/ 包含/ 科學及/ 醫學/ 各/ 領域/ 的/ 基礎/ 研究/ / 更/ 多/ Heho/ 健康/ 網/ 文章/ 糖友/ 肺炎/ 風險/ 高/ 2.8/ 倍/ / 醫加/ 打/ 肺炎/ 鏈/ 球菌/ 疫苗/ 保/ 健康/ 讓/ 其他/ 細胞/ 分泌/ 胰島素/ / 動物/ 實驗/ 逆轉/ 糖尿病/ / / 文林/ 以/ 璿/ / 圖許/ 嘉真 Default為精確模式: 腰頸/ 疼痛/ 是/ 常見/ 的/ 肌肉/ 骨骼/ 疾病/ 根據/ 統計大約/ 80%/ 的/ 成年人/ 會經歷/ 腰痛/ 47%/ 的/ 人會/ 經歷/ 脖子/ 痛同樣/ 糖尿病/ 也/ 是/ 一種/ 越來/ 越/ 普遍/ 的/ 慢性病/ / / 全球/ 大約/ 有/ 3.82/ 億人/ 患有/ 這種/ 代謝/ 疾病/ / 近日/ 一項/ 刊載/ 於/ PLOS/ / ONE/ 期刊/ 的/ 研究/ 指出/ 與/ 沒/ 有/ 糖尿病/ 的/ 人/ 相比/ 糖尿病/ 患者/ 發生/ 腰痛/ 的/ 風險/ 要/ 高/ 35%/ 脖子/ 痛/ 的/ 風險/ 要/ 高/ 24%/ 糖尿病/ 患者/ 更/ 容易/ 出現/ 慢性/ 軀體/ 疼痛/ 包括/ 糖尿病/ 周圍/ 神經/ 病變/ 而且/ 同時/ 患有/ 糖尿病/ 和/ 肌肉/ 骨骼/ 疼痛/ 會導致/ 更/ 高/ 程度/ 的/ 疼痛/ 殘疾/ 和/ 心理/ 困擾/ 其/ 所/ 帶/ 來/ 的/ 負擔/ 遠遠大/ 於僅/ 患有/ 其中/ 一種/ 疾病/ / 而/ 糖尿病/ 和/ 背痛/ 也/ 有/ 共同/ 的/ 危險/ 因素/ 比如/ 說/ 肥胖/ 缺乏/ 體育/ 年/ 輕/ 的/ 時候/ 身體/ 質量/ 指數/ BMI/ 越高/ 的/ 人/ 在/ 晚年/ 患/ 糖尿病/ 的/ 可能性/ 要/ 高出/ 9/ 倍/ 以上/ ;/ 同樣/ 的/ 肥胖/ 是/ 導致/ 嚴重/ 腰痛/ 的/ 重要/ 因子/ 糖尿病/ 患者/ 也/ 不太可能/ 經常/ 參加/ 運動/ 活動/ 因此/ 有/ 較/ 高/ 的/ 風險/ 發展/ 成/ 慢性/ 肌肉/ 骨骼/ 疾病/ 如/ 背部/ 和/ 頸部/ 疼痛/ / 過去/ 的/ 研究/ 表明/ 糖尿病/ 患者/ 可能/ 會/ 因為/ 繼發性/ 糖尿病/ 相關/ 的/ 腰椎/ 間盤/ 微血管/ 病變/ 而/ 發展/ 為/ 腰椎/ 間盤/ 疾病/ 此外/ 糖尿病/ 動物/ 模型/ 中椎間/ 盤/ 退變/ 更佳/ 迅速/ / 該論文/ 的/ 作者/ Manuela/ / Ferreira/ 副教授/ 說/ 目前/ 還沒有/ 足夠/ 的/ 證據/ 證明/ 糖尿病/ 與/ 腰/ 頸/ 疼痛/ 之間/ 存在/ 因果/ 關/ 係/ 但/ 這種/ 積極/ 聯/ 繫/ 值得/ 進/ 一步/ 調查/ 和/ 研究/ 論文/ 還建議/ 醫護/ 人員應/ 該/ 考慮/ 對長/ 期頸痛/ 或/ 腰痛/ 患者/ 進行/ 糖尿病/ 篩查/ / 越來/ 越/ 多/ 的/ 人/ 同時/ 受到/ 頸/ 背/ 疼痛/ 和/ 糖尿病/ 的/ 折磨/ 論文/ 共同/ 作者/ Paulo/ / Ferreira/ 說道/ 所以/ 值得/ 投入/ 更/ 多/ 的/ 資源/ 來/ 研究/ 它們/ 之間/ 的/ 相互/ 關/ 係/ 改變/ 糖尿病/ 的/ 治療/ 干預/ 措施/ 可/ 或/ 許以/ 減少/ 背痛/ 的/ 發病率/ 反之亦然/ / 參考/ 資料/ Study/ / links/ / diabetes/ / and/ / back/ / pain/ / 期刊/ 小檔案/ PLOS/ / ONE/ 為/ 一份/ 同行/ 評審/ 的/ 開放/ 獲取/ 科學/ 期刊/ 由/ 公共/ 科學/ 圖書館/ 自/ 2006/ 年/ 發行/ 為/ 全世界/ 文章/ 刊載/ 數量/ 最/ 多/ 的/ 期刊/ 所刊/ 載/ 的/ 文章/ 包含/ 科學及/ 醫學/ 各/ 領域/ 的/ 基礎/ 研究/ / 更/ 多/ Heho/ 健康/ 網/ 文章/ 糖友/ 肺炎/ 風險/ 高/ 2.8/ 倍/ / 醫加/ 打/ 肺炎/ 鏈/ 球菌/ 疫苗/ 保/ 健康/ 讓/ 其他/ 細胞/ 分泌/ 胰島素/ / 動物/ 實驗/ 逆轉/ 糖尿病/ / / 文林/ 以/ 璿/ / 圖許/ 嘉真 搜索引擎模式: 腰頸/ 疼痛/ 是/ 常見/ 的/ 肌肉/ 骨骼/ 疾病/ 根據/ 統計大約/ 80%/ 的/ 成年/ 成年人/ 會經歷/ 腰痛/ 47%/ 的/ 人會/ 經歷/ 脖子/ 痛同樣/ 糖尿/ 糖尿病/ 也/ 是/ 一種/ 越來/ 越/ 普遍/ 的/ 慢性/ 性病/ 慢性病/ / / 全球/ 大約/ 有/ 3.82/ 億人/ 患有/ 這種/ 代謝/ 疾病/ / 近日/ 一項/ 刊載/ 於/ PLOS/ / ONE/ 期刊/ 的/ 研究/ 指出/ 與/ 沒/ 有/ 糖尿/ 糖尿病/ 的/ 人/ 相比/ 糖尿/ 糖尿病/ 患者/ 發生/ 腰痛/ 的/ 風險/ 要/ 高/ 35%/ 脖子/ 痛/ 的/ 風險/ 要/ 高/ 24%/ 糖尿/ 糖尿病/ 患者/ 更/ 容易/ 出現/ 慢性/ 軀體/ 疼痛/ 包括/ 糖尿/ 糖尿病/ 周圍/ 神經/ 病變/ 而且/ 同時/ 患有/ 糖尿/ 糖尿病/ 和/ 肌肉/ 骨骼/ 疼痛/ 會導致/ 更/ 高/ 程度/ 的/ 疼痛/ 殘疾/ 和/ 心理/ 困擾/ 其/ 所/ 帶/ 來/ 的/ 負擔/ 遠遠大/ 於僅/ 患有/ 其中/ 一種/ 疾病/ / 而/ 糖尿/ 糖尿病/ 和/ 背痛/ 也/ 有/ 共同/ 的/ 危險/ 因素/ 比如/ 說/ 肥胖/ 缺乏/ 體育/ 年/ 輕/ 的/ 時候/ 身體/ 質量/ 指數/ BMI/ 越高/ 的/ 人/ 在/ 晚年/ 患/ 糖尿/ 糖尿病/ 的/ 可能/ 可能性/ 要/ 高出/ 9/ 倍/ 以上/ ;/ 同樣/ 的/ 肥胖/ 是/ 導致/ 嚴重/ 腰痛/ 的/ 重要/ 因子/ 糖尿/ 糖尿病/ 患者/ 也/ 可能/ 不太可能/ 經常/ 參加/ 運動/ 活動/ 因此/ 有/ 較/ 高/ 的/ 風險/ 發展/ 成/ 慢性/ 肌肉/ 骨骼/ 疾病/ 如/ 背部/ 和/ 頸部/ 疼痛/ / 過去/ 的/ 研究/ 表明/ 糖尿/ 糖尿病/ 患者/ 可能/ 會/ 因為/ 繼發性/ 糖尿/ 糖尿病/ 相關/ 的/ 腰椎/ 間盤/ 血管/ 微血管/ 病變/ 而/ 發展/ 為/ 腰椎/ 間盤/ 疾病/ 此外/ 糖尿/ 糖尿病/ 動物/ 模型/ 中椎間/ 盤/ 退變/ 更佳/ 迅速/ / 該論文/ 的/ 作者/ Manuela/ / Ferreira/ 教授/ 副教授/ 說/ 目前/ 還沒有/ 足夠/ 的/ 證據/ 證明/ 糖尿/ 糖尿病/ 與/ 腰/ 頸/ 疼痛/ 之間/ 存在/ 因果/ 關/ 係/ 但/ 這種/ 積極/ 聯/ 繫/ 值得/ 進/ 一步/ 調查/ 和/ 研究/ 論文/ 還建議/ 醫護/ 人員應/ 該/ 考慮/ 對長/ 期頸痛/ 或/ 腰痛/ 患者/ 進行/ 糖尿/ 糖尿病/ 篩查/ / 越來/ 越/ 多/ 的/ 人/ 同時/ 受到/ 頸/ 背/ 疼痛/ 和/ 糖尿/ 糖尿病/ 的/ 折磨/ 論文/ 共同/ 作者/ Paulo/ / Ferreira/ 說道/ 所以/ 值得/ 投入/ 更/ 多/ 的/ 資源/ 來/ 研究/ 它們/ 之間/ 的/ 相互/ 關/ 係/ 改變/ 糖尿/ 糖尿病/ 的/ 治療/ 干預/ 措施/ 可/ 或/ 許以/ 減少/ 背痛/ 的/ 發病率/ 反之/ 亦然/ 反之亦然/ / 參考/ 資料/ Study/ / links/ / diabetes/ / and/ / back/ / pain/ / 期刊/ 小檔案/ PLOS/ / ONE/ 為/ 一份/ 同行/ 評審/ 的/ 開放/ 獲取/ 科學/ 期刊/ 由/ 公共/ 科學/ 圖書館/ 自/ 2006/ 年/ 發行/ 為/ 世界/ 全世界/ 文章/ 刊載/ 數量/ 最/ 多/ 的/ 期刊/ 所刊/ 載/ 的/ 文章/ 包含/ 科學及/ 醫學/ 各/ 領域/ 的/ 基礎/ 研究/ / 更/ 多/ Heho/ 健康/ 網/ 文章/ 糖友/ 肺炎/ 風險/ 高/ 2.8/ 倍/ / 醫加/ 打/ 肺炎/ 鏈/ 球菌/ 疫苗/ 保/ 健康/ 讓/ 其他/ 細胞/ 分泌/ 胰島素/ / 動物/ 實驗/ 逆轉/ 糖尿/ 糖尿病/ / / 文林/ 以/ 璿/ / 圖許/ 嘉真 |
5.將字詞頻率以word cloud(文字雲)呈現
將字詞頻率以文字雲繪出
載入文字雲套件
|
1 2 |
import matplotlib.pyplot as plt from wordcloud import WordCloud |
設定停用字stopwords(排除常用詞、無法代表特殊意義的字詞),投入WordClour()函數中,其中參數stopwords形式可以是:
- dictionary {key : value}的格式
- set {‘a’, ‘b’, ‘c’, …}的格式
*stopwords中, \n 是前面因為避免印出一長串沒有換行符號的article而加入的,故這邊再另外挑除
|
1 2 3 |
# 設定停用字詞 stopwords = {}.fromkeys(["也","但","來","個","再","的","和","是","有","更","會","可能","有何","從","對","就", '\n','越','為','這種','多','越來',' ']) #stopwords = {"也","但","來","個","再","的","和","是","有","更","會","可能","有何","從","對","就",'\n','越','為','這種','多','越來',' '} |
產生文字雲(方法1): 使用generate_from_frequencies()
- generate_from_frequencies()方法會忽略stopwords參數的部分,故在產生hash dictionary字詞頻率的時候,須先自行處理挑除stopwords的部分。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
# 使用cut_for_search(搜尋引擎)斷詞模式並產生字詞頻率的dictionary (並剔除stopwords的計算) Sentence = jieba.cut_for_search(d) # create a python dictionary hash = {} for item in Sentence: if item in stopwords: continue if item in hash: hash[item] += 1 else: hash[item] = 1 # 文字雲樣式設定 wc = WordCloud(font_path="/Users/hsuanlee/Library/Fonts/NotoSansCJKtc-Regular.otf", #設置字體 background_color="white", #背景顏色 max_words = 2000 , #文字雲顯示最大詞數 stopwords=stopwords) #停用字詞 # 使用dictionary的內容產生文字雲 wc.generate_from_frequencies(hash) # 視覺化呈現 plt.imshow(wc) plt.axis("off") plt.figure(figsize=(20,10), dpi =200) plt.show() |

產生文字雲(方法2): 使用generate_from_text()
- 由於generate_from_text()方法會採納stopwords參數,故事前不需要特別對text做stopwords的挑除
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
Sentence = jieba.cut_for_search(d) text = ' '.join(Sentence) # 文字雲樣式設定 wc = WordCloud(font_path="/Users/hsuanlee/Library/Fonts/NotoSansCJKtc-Regular.otf", #設置字體 background_color="white", #背景顏色 max_words = 2000 , #文字雲顯示最大詞數 stopwords=stopwords) #停用字詞 # 直接使用結巴斷詞後的文字來產生文字雲 wc.generate_from_text(text) # 視覺化呈現 plt.imshow(wc) plt.axis("off") plt.figure(figsize=(20,10), dpi =200) plt.show() |

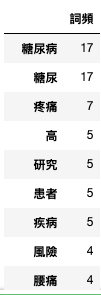
6. 將dictionary轉換成data frame(並以key當作row: orient = ‘index’)
將字詞頻率統計表依照「詞頻」由多至寡排列。
|
1 2 |
artDf = pd.DataFrame.from_dict(hash, orient='index', columns = ['詞頻']) artDf.sort_values(by= ['詞頻'], ascending= False) |
文章參考連結:
Python網路爬蟲:大數據擷取、清洗、儲存與分析:王者歸來
更多Python網路爬蟲學習筆記:
網路爬蟲 Web Crawler | 資料不求人 基礎篇 | using Python BeautifulSoup