



Logistic Regression, 羅吉斯回歸模型,適用於預測二元類別目標變數的發生機率(p),和線性回歸模型類似,與線性回歸主要不同之處在於:(1) 目標變數是目標事件發生機率P經過log函數轉換成log odds值才進行線性預測,且(2)羅吉斯回歸的各項參數是透過最大概似法(MLE)進行估計的。
Logistic Regression 羅吉斯回歸模型簡介
線性迴歸模型是用來預測連續型變數,而羅吉斯回歸則是用來預測類別型變數。
羅吉斯回歸和線性回歸模型類似,只不過預測類別目標變數是經過log函數轉換才投入線性模型中的。羅吉斯回歸方程式將類別目標變數轉換為事件的log odds值,也就是\(\log\lgroup\frac{P_{i}}{1-P_{i}}\rgroup\),來預測Z與預測變數間(X1~Xn)的線性關係。
羅吉斯回歸方程式:
$$Z_{i}=\log\lgroup\frac{P_{i}}{1-P_{i}}\rgroup=\beta_{0}+\beta_{1}*x_{1}+…+\beta_{n}*x_{n}$$
其中:
(1) \(P_{i}\)為事件發生的機率值。
(2) \(\lgroup\frac{P_{i}}{1-P_{i}}\rgroup\)為勝算比(Odds Ratio)。
在R語言中,上述模型可透過glm()函式,將參數設定為family=”binomial”來執行。
但因為我們真正關心的是模型預測的事件發生機率值Pi。所以,預測結果則透過plogis()函數將事件的log odds轉換為Pi。轉換公式如下:
$$P_{i}=1-\lgroup\frac{1}{1+e_{i}^z}\rgroup$$
羅吉斯回歸透過log函數轉換,產生了一個臨界遞增的S型函數,適用於分析機率模型。
而不同於線性迴歸,羅吉斯回歸分析的各項參數係數,是透過最大概似法(MLE)進行估計。
分析資料與問題
Problem: 預測薪資大於50K(ABOVE50K)的影響特徵因素有哪些?
Data: adult dataset (snapshot)
目標變數(1):ABOVE50K
預測變數(13):AGE, WORKCLASS, EDUCATION, EDUCATIONNUM, MARITALSTATUS, OCCUPATION, RELATIONSHIP, RACE, SEX, CAPITALGAIN, CAPITALLOSS, HOURSPERWEEK, NATIVECOUNTRY
分析步驟
(part 1 篇會說明步驟1~5的部分)
- 資料載入與檢視
- 資料探勘
- 資料前處理
- 產生訓練資料集與測試資料集
- 計算特徵變數IV值(Information Value),篩選變數
- 訓練模型與預測
- 模型診斷與調整
- 模型比較(v.s. Machine Learning Methods)
1. 資料載入與檢視
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# download from google drive's shareable link: # https://drive.google.com/file/d/1L71tumU33xmVa2EtxjTyrZ2F6CaXn9iR/view?usp=sharing id inputData # 摘要資料集 summary(inputData) # AGE WORKCLASS FNLWGT EDUCATION # Min. :17.00 Private :22696 Min. : 12285 HS-grad :10501 # 1st Qu.:28.00 Self-emp-not-inc: 2541 1st Qu.: 117827 Some-college: 7291 # Median :37.00 Local-gov : 2093 Median : 178356 Bachelors : 5355 # Mean :38.58 ? : 1836 Mean : 189778 Masters : 1723 # 3rd Qu.:48.00 State-gov : 1298 3rd Qu.: 237051 Assoc-voc : 1382 # Max. :90.00 Self-emp-inc : 1116 Max. :1484705 11th : 1175 # (Other) : 981 (Other) : 5134 # EDUCATIONNUM MARITALSTATUS OCCUPATION # Min. : 1.00 Divorced : 4443 Prof-specialty :4140 # 1st Qu.: 9.00 Married-AF-spouse : 23 Craft-repair :4099 # Median :10.00 Married-civ-spouse :14976 Exec-managerial:4066 # Mean :10.08 Married-spouse-absent: 418 Adm-clerical :3770 # 3rd Qu.:12.00 Never-married :10683 Sales :3650 # Max. :16.00 Separated : 1025 Other-service :3295 # Widowed : 993 (Other) :9541 # RELATIONSHIP RACE SEX # Husband :13193 Amer-Indian-Eskimo: 311 Female:10771 # Not-in-family : 8305 Asian-Pac-Islander: 1039 Male :21790 # Other-relative: 981 Black : 3124 # Own-child : 5068 Other : 271 # Unmarried : 3446 White :27816 # Wife : 1568 # # CAPITALGAIN CAPITALLOSS HOURSPERWEEK NATIVECOUNTRY # Min. : 0 Min. : 0.0 Min. : 1.00 United-States:29170 # 1st Qu.: 0 1st Qu.: 0.0 1st Qu.:40.00 Mexico : 643 # Median : 0 Median : 0.0 Median :40.00 ? : 583 # Mean : 1078 Mean : 87.3 Mean :40.44 Philippines : 198 # 3rd Qu.: 0 3rd Qu.: 0.0 3rd Qu.:45.00 Germany : 137 # Max. :99999 Max. :4356.0 Max. :99.00 Canada : 121 # (Other) : 1709 # ABOVE50K # Min. :0.0000 # 1st Qu.:0.0000 # Median :0.0000 # Mean :0.2408 # 3rd Qu.:0.0000 # Max. :1.0000 |
由於我們的目標變數目前是數值0,1,為了後續分析,我們決定(1)ABOVE50K轉變成(<=50K, >50K)的factor變數,並(2)另外新增ABOVE50K_y(0,1)的factor變數。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# 將ABOVE50K原始0,1轉換成 50K的factor資料類型 inputData$ABOVE50K 50K')) # 產生新factor變數ABOVE50K_y: library(dplyr) inputData$ABOVE50K_y inputData$ABOVE50K == ">50K" ~ 1)) # 確認轉換後的變數沒有問題 summary(inputData$ABOVE50K) # 50K # 24720 7841 summary(inputData$ABOVE50K_y) # 0 1 # 24720 7841 |
最後再確認一次資料集所有變數型態。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
# 查看資料結構:資料變數、型態 str(inputData) # 'data.frame': 32561 obs. of 16 variables: # $ AGE : int 39 50 38 53 28 37 49 52 31 42 ... # $ WORKCLASS : Factor w/ 9 levels " ?"," Federal-gov",..: 8 7 5 5 5 5 5 7 5 5 ... # $ FNLWGT : int 77516 83311 215646 234721 338409 284582 160187 209642 45781 159449 ... # $ EDUCATION : Factor w/ 16 levels " 10th"," 11th",..: 10 10 12 2 10 13 7 12 13 10 ... # $ EDUCATIONNUM : int 13 13 9 7 13 14 5 9 14 13 ... # $ MARITALSTATUS: Factor w/ 7 levels " Divorced"," Married-AF-spouse",..: 5 3 1 3 3 3 4 3 5 3 ... # $ OCCUPATION : Factor w/ 15 levels " ?"," Adm-clerical",..: 2 5 7 7 11 5 9 5 11 5 ... # $ RELATIONSHIP : Factor w/ 6 levels " Husband"," Not-in-family",..: 2 1 2 1 6 6 2 1 2 1 ... # $ RACE : Factor w/ 5 levels " Amer-Indian-Eskimo",..: 5 5 5 3 3 5 3 5 5 5 ... # $ SEX : Factor w/ 2 levels " Female"," Male": 2 2 2 2 1 1 1 2 1 2 ... # $ CAPITALGAIN : int 2174 0 0 0 0 0 0 0 14084 5178 ... # $ CAPITALLOSS : int 0 0 0 0 0 0 0 0 0 0 ... # $ HOURSPERWEEK : int 40 13 40 40 40 40 16 45 50 40 ... # $ NATIVECOUNTRY: Factor w/ 42 levels " ?"," Cambodia",..: 40 40 40 40 6 40 24 40 40 40 ... # $ ABOVE50K : Factor w/ 2 levels "50K": 1 1 1 1 1 1 1 2 2 2 ... # $ ABOVE50K_y : Factor w/ 2 levels "0","1": 1 1 1 1 1 1 1 2 2 2 ... |
幾個光看變數名稱不足以了解的變數說明如下:
(1) fnlwgt : 代表final weight,即該代表個體在母體所佔比例
(2) educatoin_num:代表受教育的時間(年份)
為了簡化分析,我們將忽略fnlwgt每個代表個體在母體中所佔比重。
2. 資料探勘(Exploratory Data Analysis)
|
1 2 3 |
# 載入繪圖所需套件 library(ggplot2) library(scales) # needed for labels=percent |
2-1. Age
查看年齡變數(AGE)各區間次數分佈與每區間薪資水準組成比例。
|
1 2 3 4 5 6 7 8 9 10 11 |
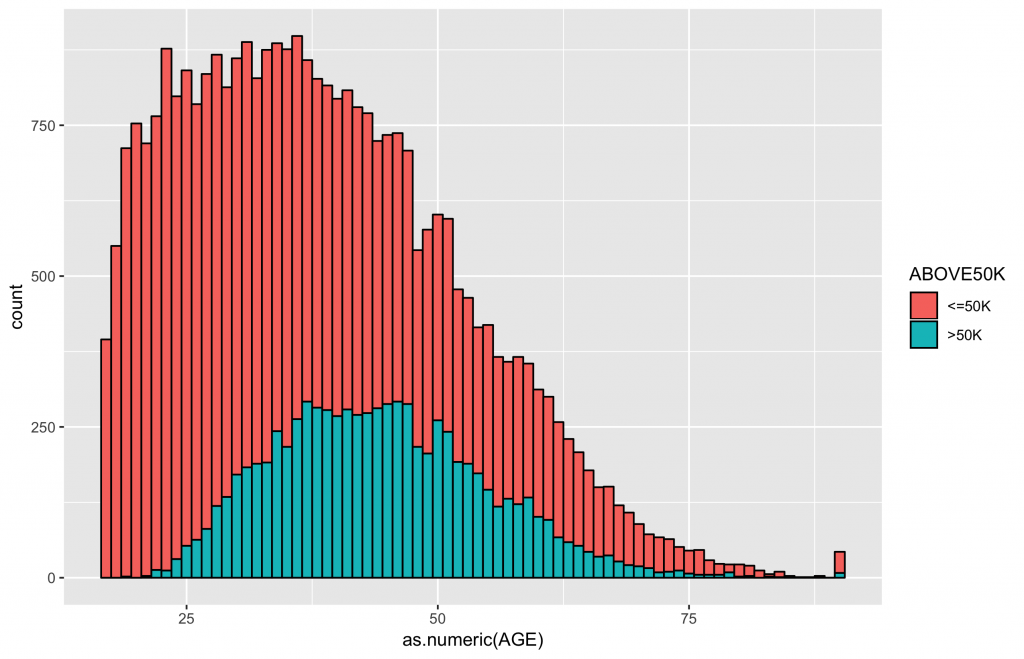
# 2-1. age summary(inputData$AGE) # Min. 1st Qu. Median Mean 3rd Qu. Max. # 17.00 28.00 37.00 38.58 48.00 90.00 gg ggplot(data = inputData, aes(x = as.numeric(AGE))) + geom_histogram(color = "black",binwidth = 1, aes(group=ABOVE50K, fill = ABOVE50K)) + geom_vline(xintercept = mean(inputData$AGE[inputData$ABOVE50K == 1]), col = "blue", lty = 5, lwd = 0.8) + geom_vline(xintercept = mean(inputData$AGE[inputData$ABOVE50K == 0]), col = "black", lty = 5, lwd = 0.8) gg |
可以發現薪資水平高於50K的年齡偏高,平均數約落在40-50歲,而薪資水平小於等於50K的族群偏年輕。
2-2. Workclass
|
1 2 3 4 5 6 7 |
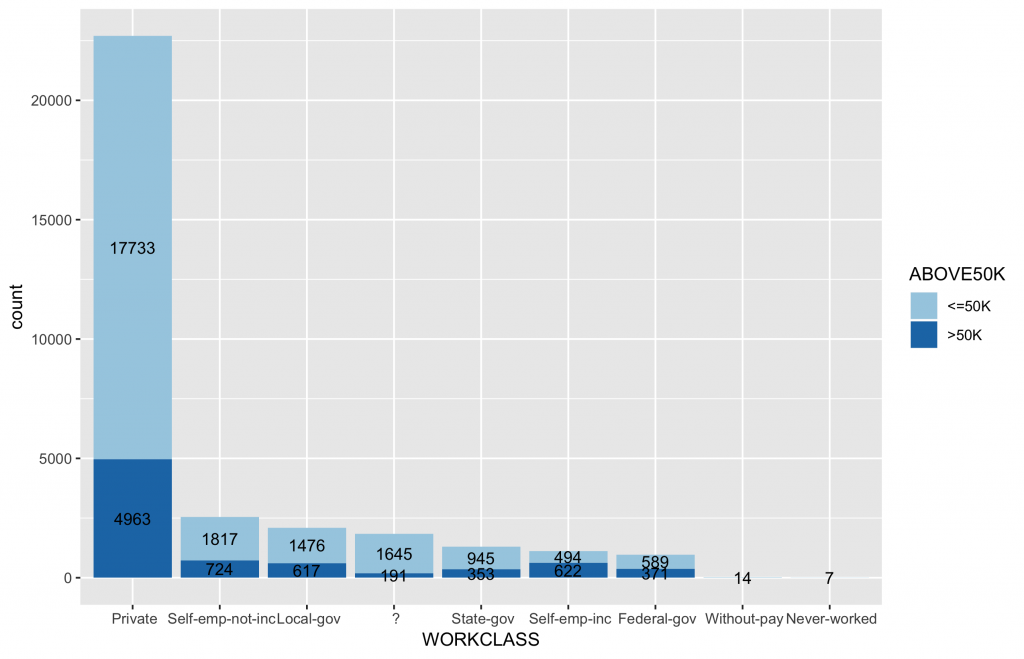
summary(inputData$WORKCLASS) # ? Federal-gov Local-gov Never-worked # 1836 960 2093 7 # Private Self-emp-inc Self-emp-not-inc State-gov # 22696 1116 2541 1298 # Without-pay # 14 |
查看workclass各類別次數分佈。
|
1 2 3 4 5 |
inputData$WORKCLASS ggplot(data = inputData, aes(x = WORKCLASS, fill = ABOVE50K)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=3.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") |
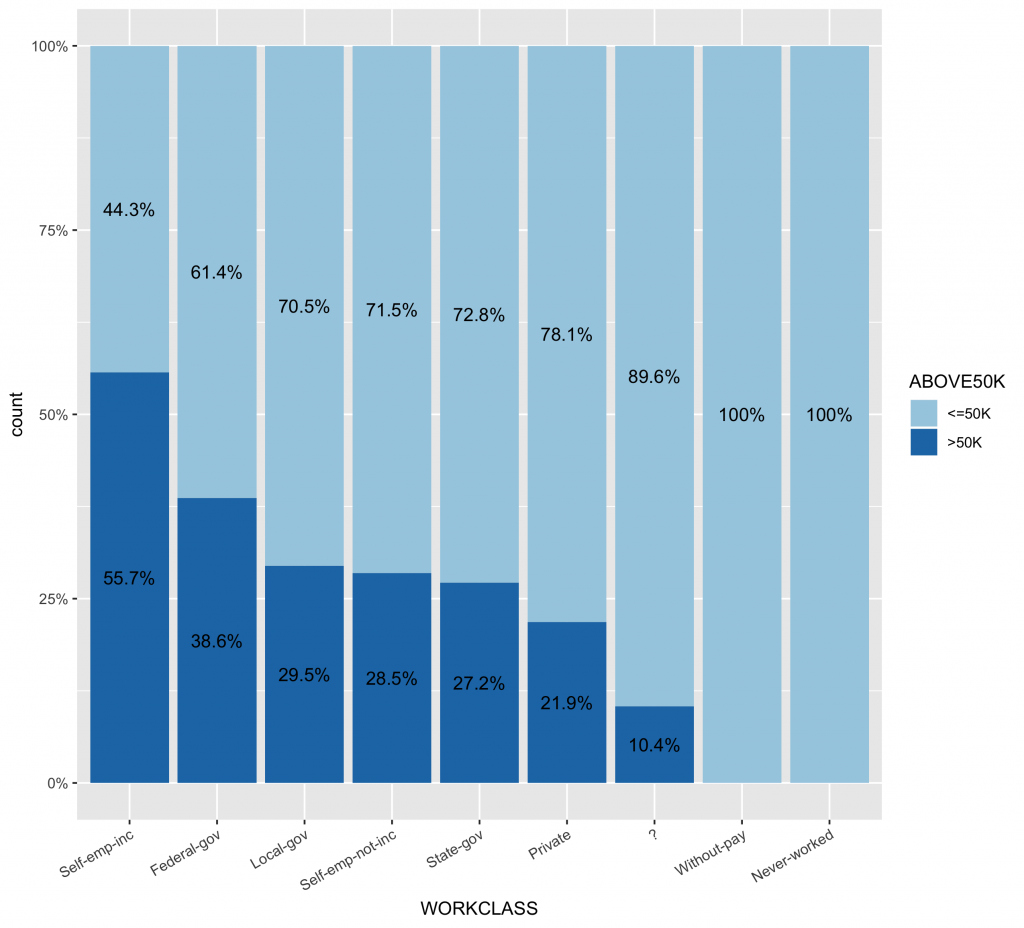
查看workclass各類別薪資水準組成比例。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 首先,先計算類別變數中,不同類別水準值中的薪資水平分佈比例 df2 df2.summary df2 %>% group_by(WORKCLASS,ABOVE50K) %>% summarise(n = n()) %>% mutate(ratio=scales::percent(n/sum(n))) # 依據ABOVE50K的比例排序,更可以看出哪些類別水準有較高ABOVE50K比例 ggplot(inputData, aes(x = forcats::fct_reorder(f = WORKCLASS, x = as.numeric(ABOVE50K),fun = mean, .desc = TRUE), fill = ABOVE50K)) + geom_bar(position = "fill") + geom_text(data=df2.summary, aes(y=n,label=ratio), position=position_fill(vjust=0.5)) + scale_y_continuous(labels = scales::percent) + scale_fill_brewer(palette="Paired") |
2-3. Education
基礎敘述統計
|
1 2 3 4 5 6 7 |
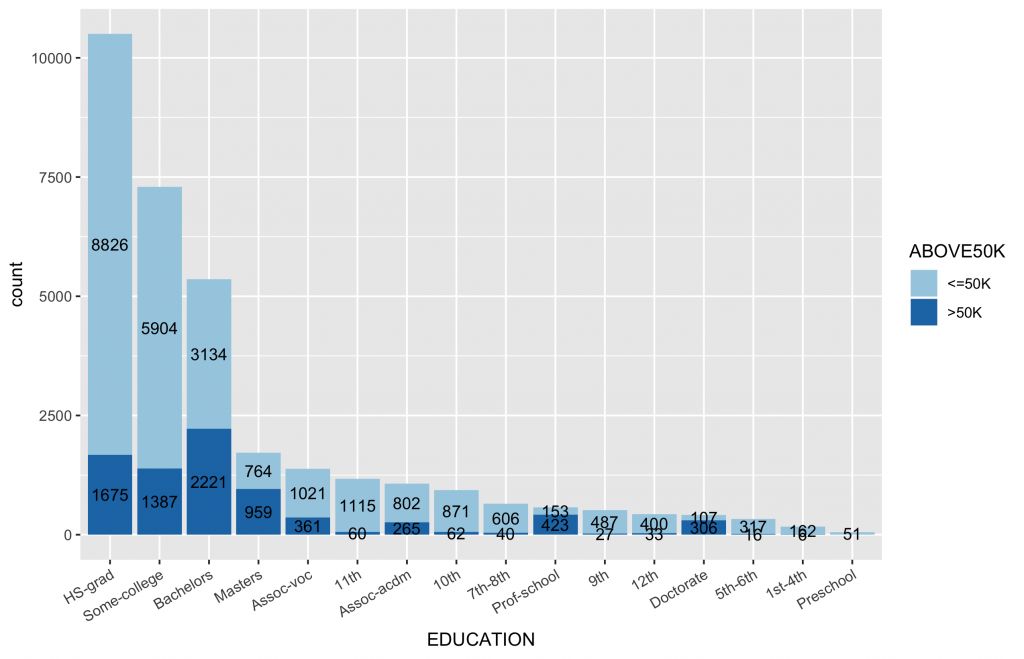
summary(inputData$EDUCATION) # 10th 11th 12th 1st-4th 5th-6th 7th-8th # 933 1175 433 168 333 646 # 9th Assoc-acdm Assoc-voc Bachelors Doctorate HS-grad # 514 1067 1382 5355 413 10501 # Masters Preschool Prof-school Some-college # 1723 51 576 7291 |
次數分配圖
|
1 2 3 4 5 6 |
inputData$EDUCATION ggplot(data = inputData, aes(x = EDUCATION, fill = ABOVE50K)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=3.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
各類別水準值中目標變數分佈圖
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 首先,先計算類別變數中,不同類別水準值中的薪資水平分佈比例 df2 df2.summary df2 %>% group_by(EDUCATION) %>% count(ABOVE50K) %>% mutate(ratio=scales::percent(n/sum(n))) %>% ungroup() # 依據ABOVE50K的比例排序,更可以看出哪些類別水準有較高ABOVE50K比例 ggplot(inputData, aes(x = forcats::fct_reorder(f = EDUCATION, x = as.numeric(ABOVE50K), fun = mean, .desc = TRUE), fill = ABOVE50K)) + geom_bar(position = "fill") + geom_text(data=df2.summary, aes(y=n,label=ratio), position=position_fill(vjust=0.5)) + scale_y_continuous(labels = scales::percent) + scale_fill_brewer(palette="Paired") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
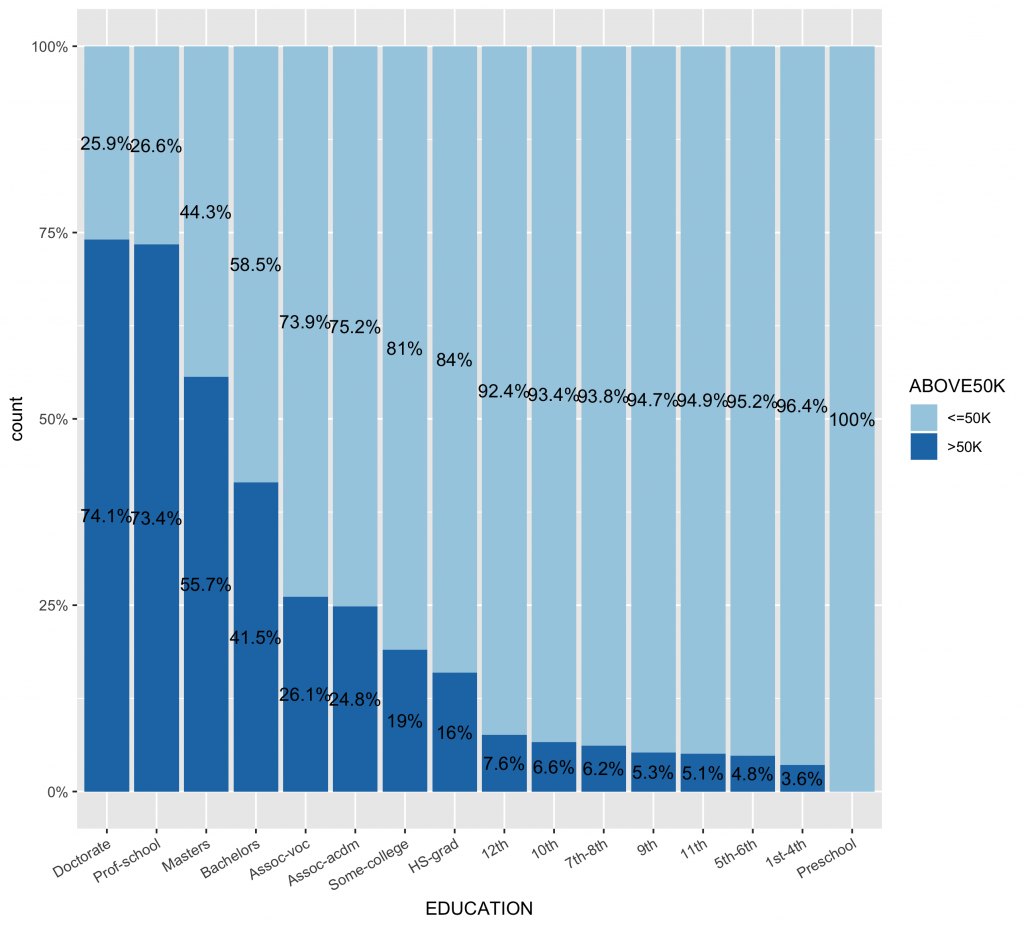
2-4. Educationnum (教育年份)
基礎敘述統計
|
1 2 3 |
summary(inputData$AGE) # Min. 1st Qu. Median Mean 3rd Qu. Max. # 17.00 28.00 37.00 38.58 48.00 90.00 |
次數分配圖
|
1 2 3 4 5 6 7 |
inputData$AGE_cut inputData$AGE_cut ggplot(data = inputData, aes(x = AGE_cut, fill = ABOVE50K)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=3.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") + labs(x = "AGE") |
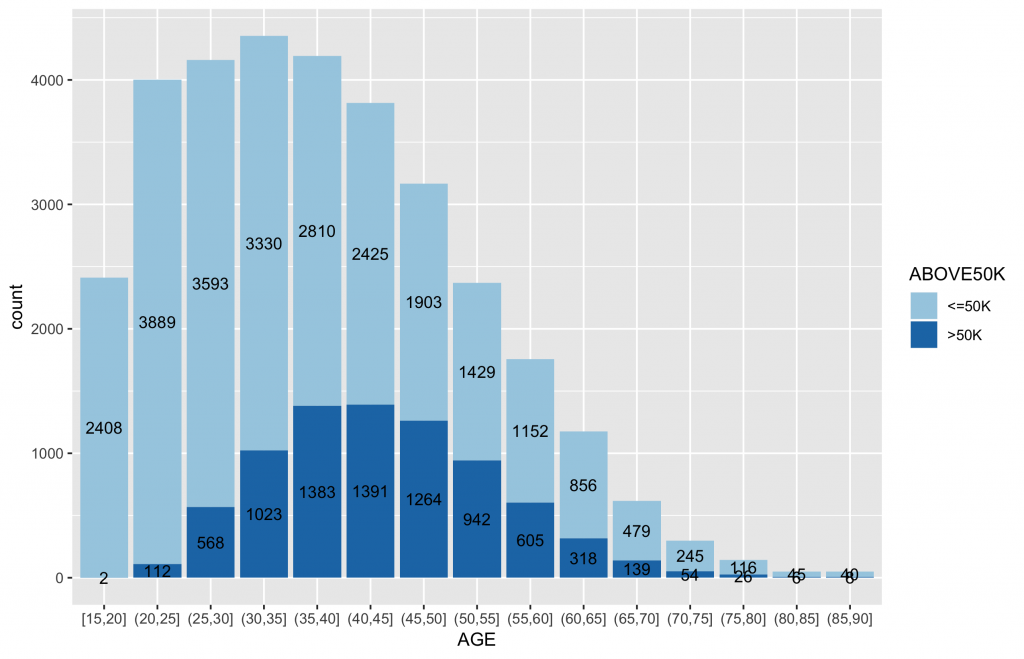
各類別水準值中目標變數分佈圖
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
# 首先,先計算類別變數中,不同類別水準值中的薪資水平分佈比例 df2 df2.summary df2 %>% group_by(AGE_cut) %>% count(ABOVE50K) %>% mutate(ratio=scales::percent(n/sum(n))) %>% ungroup() # 依據ABOVE50K的比例排序,更可以看出哪些類別水準有較高ABOVE50K比例 ggplot(inputData, aes(x = forcats::fct_reorder(f = AGE_cut, x = as.numeric(ABOVE50K), fun = mean, .desc = TRUE), fill = ABOVE50K)) + geom_bar(position = "fill") + geom_text(data=df2.summary, aes(y=n,label=ratio), position=position_fill(vjust=0.5)) + scale_y_continuous(labels = scales::percent) + scale_fill_brewer(palette="Paired") + labs(x = "AGE") |
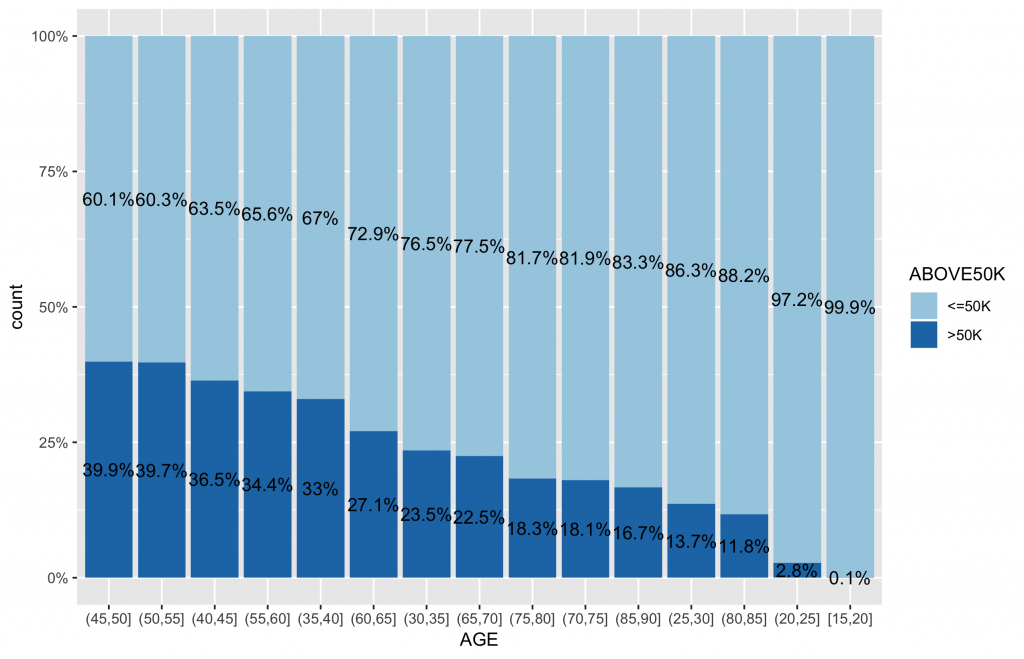
2-5. MaritalStatus
基礎敘述統計
|
1 2 3 4 5 6 7 |
summary(inputData$MARITALSTATUS) # Divorced Married-AF-spouse Married-civ-spouse # 4443 23 14976 # Married-spouse-absent Never-married Separated # 418 10683 1025 # Widowed # 993 |
次數分配圖
|
1 2 3 4 5 6 |
inputData$MARITALSTATUS ggplot(data = inputData, aes(x = MARITALSTATUS, fill = ABOVE50K)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=3.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
各類別水準值中目標變數分佈圖
|
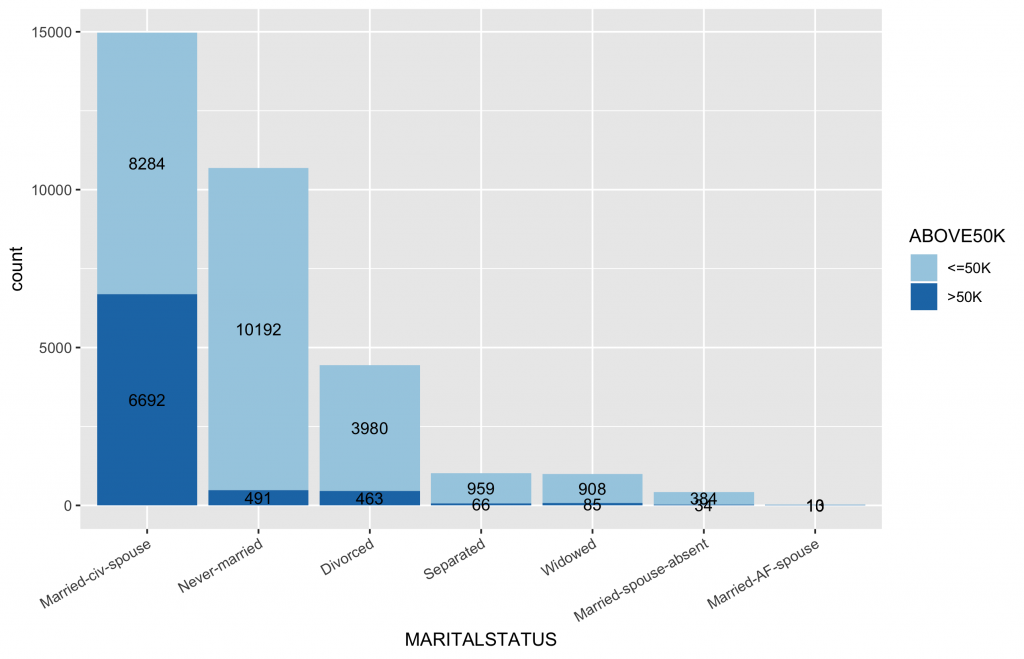
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
# 首先,先計算類別變數中,不同類別水準值中的薪資水平分佈比例 df2 df2.summary df2 %>% group_by(MARITALSTATUS) %>% count(ABOVE50K) %>% mutate(ratio=scales::percent(n/sum(n))) %>% ungroup() # 依據ABOVE50K的比例排序,更可以看出哪些類別水準有較高ABOVE50K比例 ggplot(inputData, aes(x = forcats::fct_reorder(f = MARITALSTATUS, x = as.numeric(ABOVE50K), fun = mean, .desc = TRUE), fill = ABOVE50K)) + geom_bar(position = "fill") + geom_text(data=df2.summary, aes(y=n,label=ratio), position=position_fill(vjust=0.5)) + scale_y_continuous(labels = scales::percent) + scale_fill_brewer(palette="Paired") + labs(x = "MARITALSTATUS", y = "percentage") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
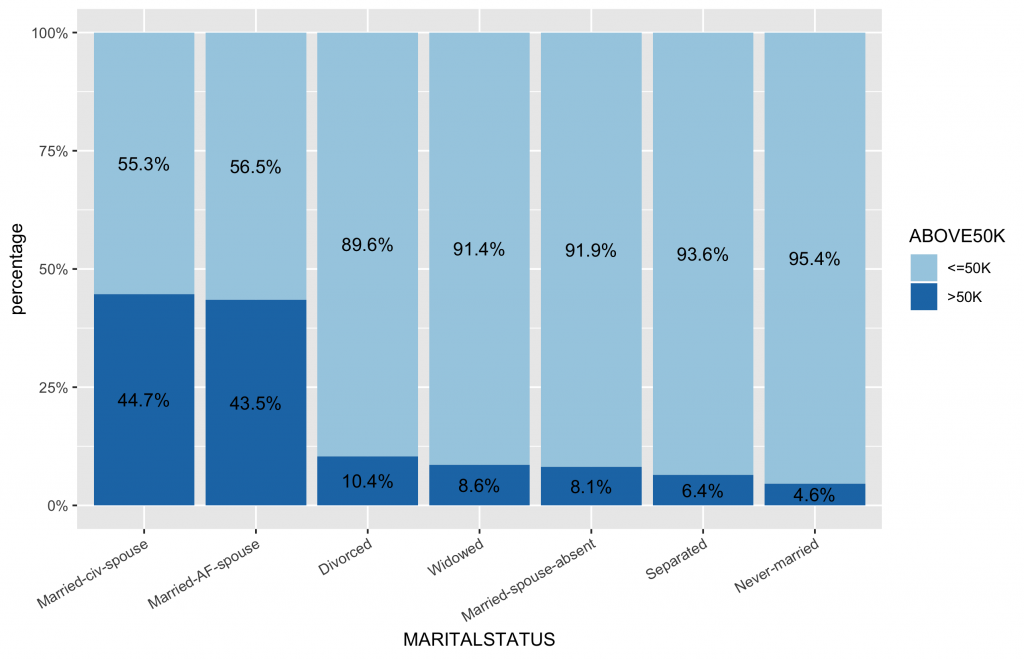
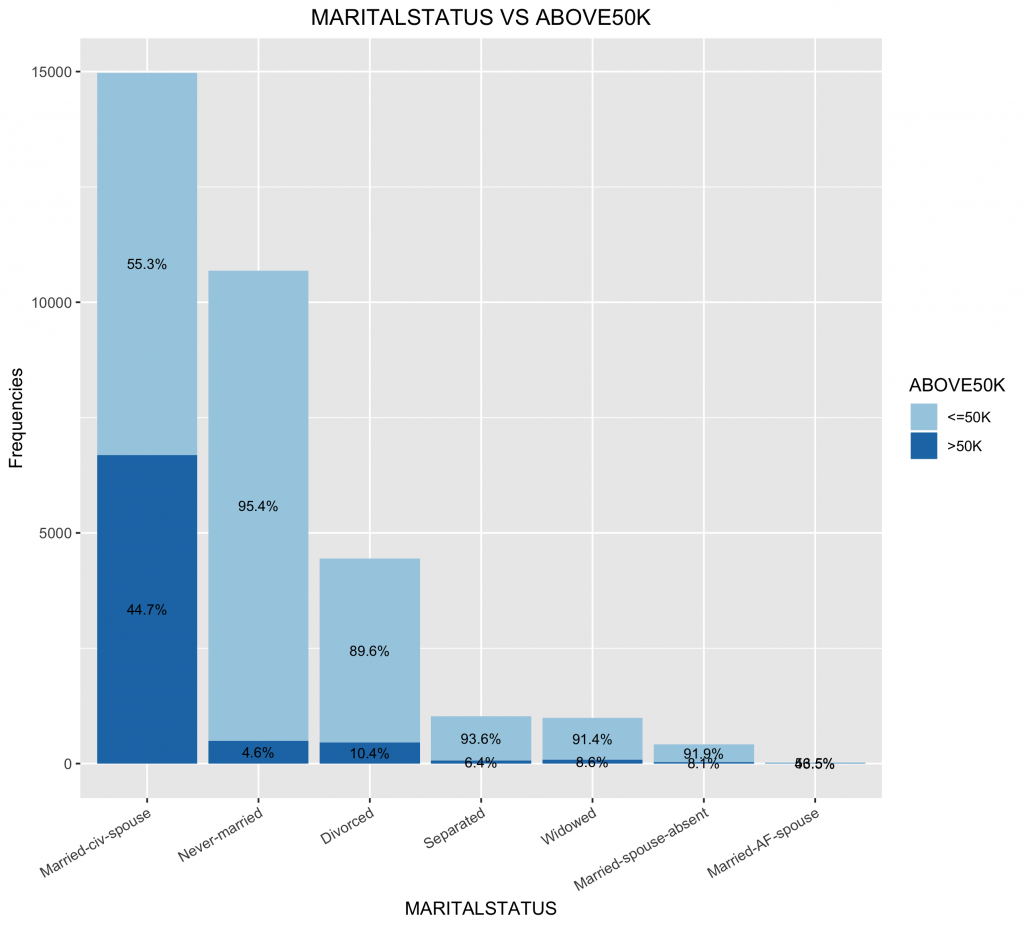
如果想要同一張圖y軸可以看到frequency,stacked bar可以看到目標類別水平的比例分佈,可以使用下面方法繪製。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# 如果想要在同一張圖同時看到frequencies & proportion: # 先新增一欄label位置的欄位 # (依照ABOVE50K的類別水準順序,計算累積數值,並將數值置中於各類別累積高度) df3.summary df2.summary %>% group_by(MARITALSTATUS) %>% #因為繪圖資訊是先畫>50K,再畫 do( data.frame(with(data=., .[order(desc(ABOVE50K)),] )) ) %>% ungroup() %>% group_by(MARITALSTATUS) %>% mutate(pos = (cumsum(n) - (0.5 * n))) %>% as.data.frame() %>% ungroup() ggplot(data = df3.summary,mapping = aes(x = MARITALSTATUS, y = n, fill = ABOVE50K)) + geom_bar(stat = "identity") + geom_text(mapping = aes(y = pos, label = ratio), size = 3) + scale_fill_brewer(palette="Paired") + labs(title = "MARITALSTATUS VS ABOVE50K", x = "MARITALSTATUS", y = "Frequencies") + # Add Title and Labels theme(plot.title = element_text(hjust = 0.5)) # Change the appearance of the main title |
2-6. Occupation職業
基礎敘述統計
|
1 2 3 4 5 6 7 8 9 |
summary(inputData$OCCUPATION) # ? Adm-clerical Armed-Forces Craft-repair # 1843 3770 9 4099 # Exec-managerial Farming-fishing Handlers-cleaners Machine-op-inspct # 4066 994 1370 2002 # Other-service Priv-house-serv Prof-specialty Protective-serv # 3295 149 4140 649 # Sales Tech-support Transport-moving # 3650 928 1597 |
可以發現類別水準值滿複雜的。
次數分配圖
|
1 2 3 4 5 6 |
inputData$OCCUPATION ggplot(data = inputData, aes(x = OCCUPATION, fill = ABOVE50K)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=3.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
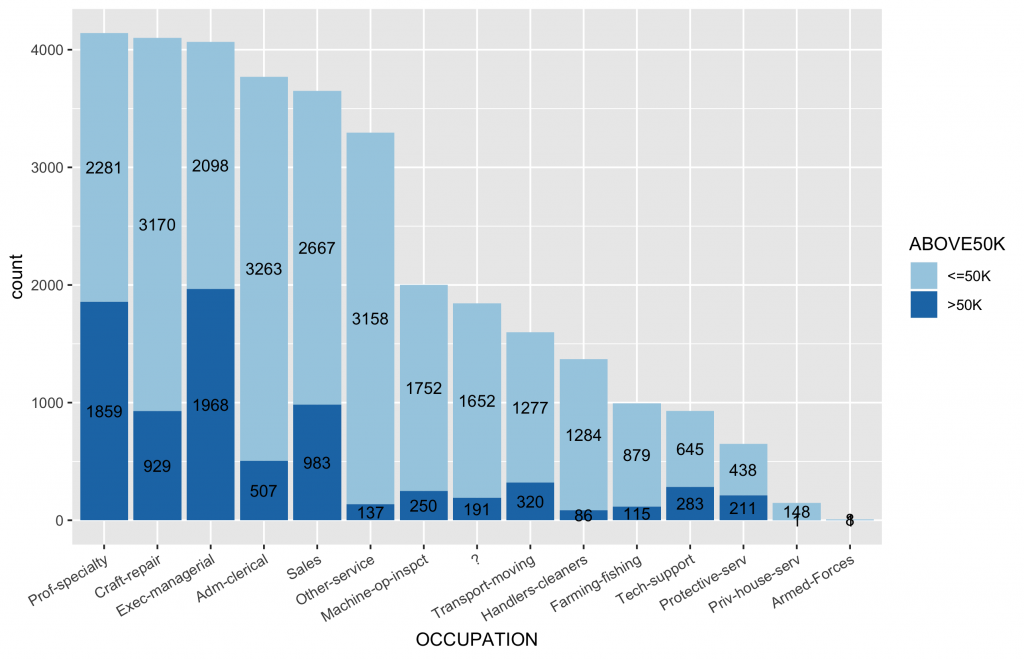
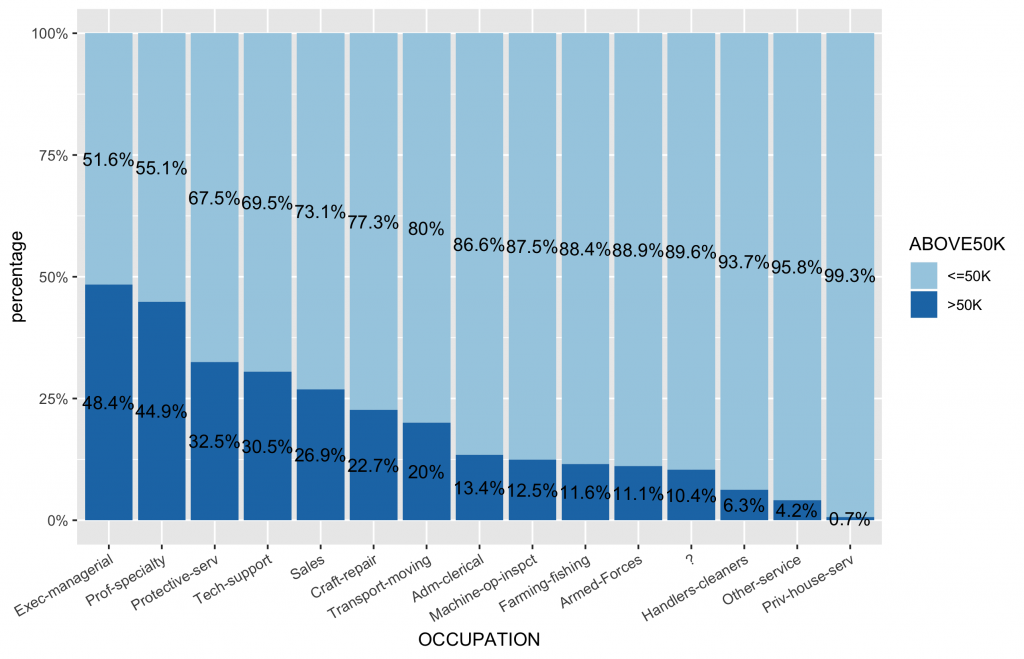
各類別水準值中目標變數分佈圖
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 首先,先計算類別變數中,不同類別水準值中的薪資水平分佈比例 df2 df2.summary df2 %>% group_by(OCCUPATION) %>% count(ABOVE50K) %>% mutate(ratio=scales::percent(n/sum(n))) %>% as.data.frame() %>% ungroup() # 依據ABOVE50K的比例排序,更可以看出哪些類別水準有較高ABOVE50K比例 ggplot(inputData, aes(x = forcats::fct_reorder(f = OCCUPATION, x = as.numeric(ABOVE50K), fun = mean, .desc = TRUE), fill = ABOVE50K)) + geom_bar(position = "fill") + geom_text(data=df2.summary, aes(y=n,label=ratio), position=position_fill(vjust=0.5)) + scale_y_continuous(labels = scales::percent) + scale_fill_brewer(palette="Paired") + labs(x = "OCCUPATION", y = "percentage") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
如果想要同一張圖y軸可以看到frequency,stacked bar可以看到目標類別水平的比例分佈,可以使用下面方法繪製。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
df3.summary df2.summary %>% group_by(OCCUPATION) %>% #因為繪圖資訊是先畫>50K,再畫 do( data.frame(with(data=., .[order(desc(ABOVE50K)),] )) ) %>% ungroup() %>% group_by(OCCUPATION) %>% mutate(pos = (cumsum(n) - (0.5 * n))) %>% as.data.frame() %>% ungroup() ggplot(data = df3.summary,mapping = aes(x = OCCUPATION, y = n, fill = ABOVE50K)) + geom_bar(stat = "identity") + geom_text(mapping = aes(y = pos, label = ratio), size = 3) + scale_fill_brewer(palette="Paired") + labs(title = "OCCUPATION VS ABOVE50K", x = "OCCUPATION", y = "Frequencies") + # Add Title and Labels theme(plot.title = element_text(hjust = 0.5), axis.text.x = element_text(angle = 30, hjust = 1)) |
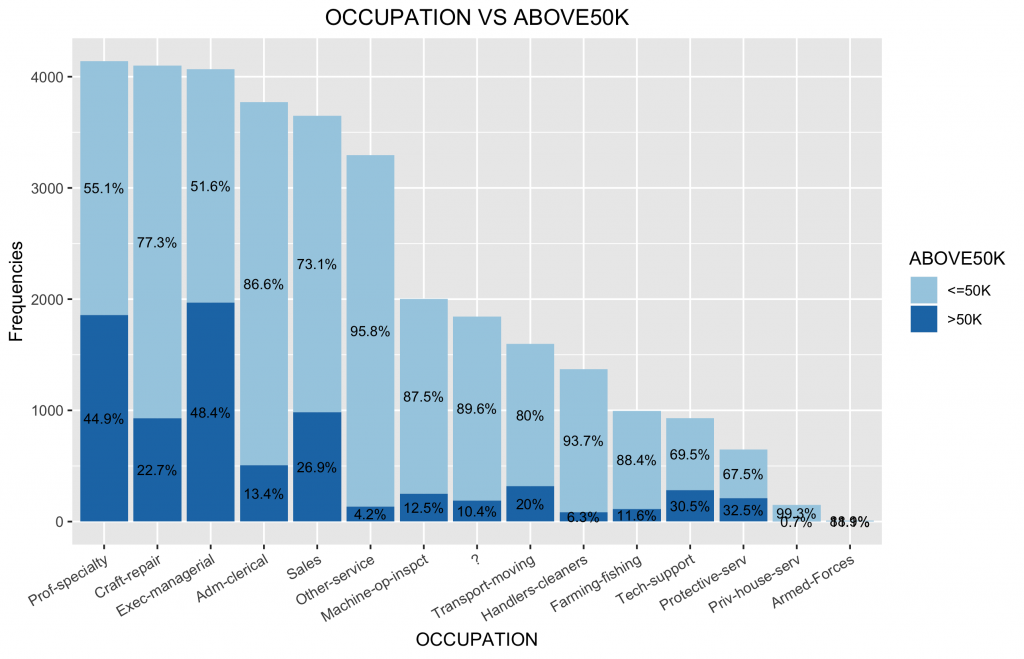
2-7. Relationship
基礎敘述統計
|
1 2 3 4 5 |
summary(inputData$RELATIONSHIP) # Husband Not-in-family Other-relative Own-child Unmarried # 13193 8305 981 5068 3446 # Wife # 1568 |
次數分配圖
|
1 2 3 4 5 |
inputData$RELATIONSHIP ggplot(data = inputData, aes(x = RELATIONSHIP, fill = ABOVE50K)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=3.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") |
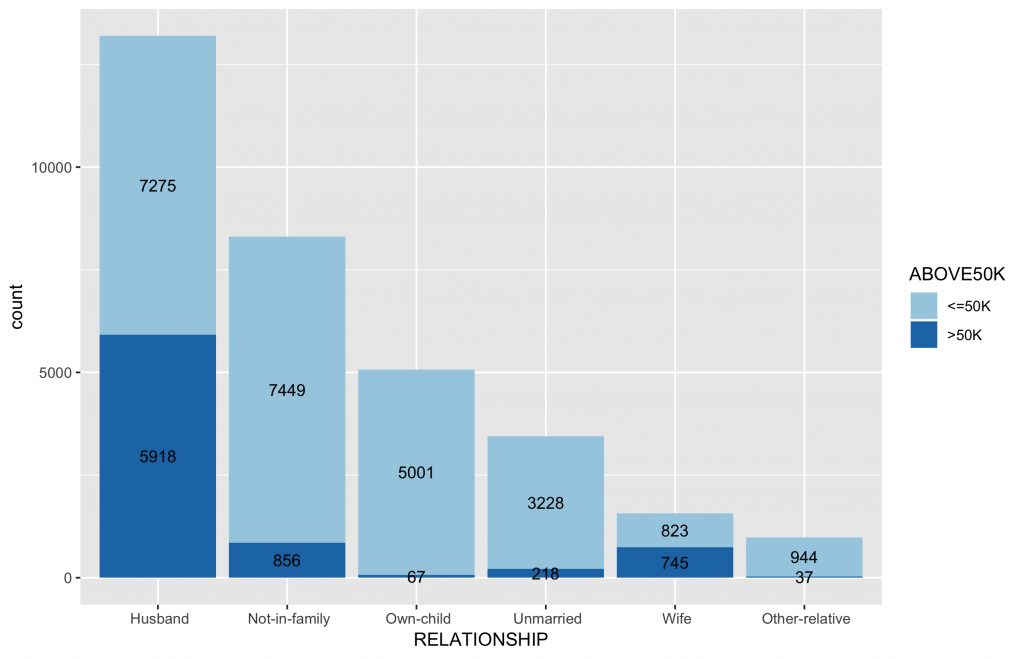
各類別水準值中目標變數分佈圖
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 首先,先計算類別變數中,不同類別水準值中的薪資水平分佈比例 df2 df2.summary df2 %>% group_by(RELATIONSHIP) %>% count(ABOVE50K) %>% mutate(ratio=scales::percent(n/sum(n))) %>% as.data.frame() %>% ungroup() # 依據ABOVE50K的比例排序,更可以看出哪些類別水準有較高ABOVE50K比例 ggplot(inputData, aes(x = forcats::fct_reorder(f = RELATIONSHIP, x = as.numeric(ABOVE50K), fun = mean, .desc = TRUE), fill = ABOVE50K)) + geom_bar(position = "fill") + geom_text(data=df2.summary, aes(y=n,label=ratio), position=position_fill(vjust=0.5)) + scale_y_continuous(labels = scales::percent) + scale_fill_brewer(palette="Paired") + labs(x = "RELATIONSHIP", y = "percentage") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
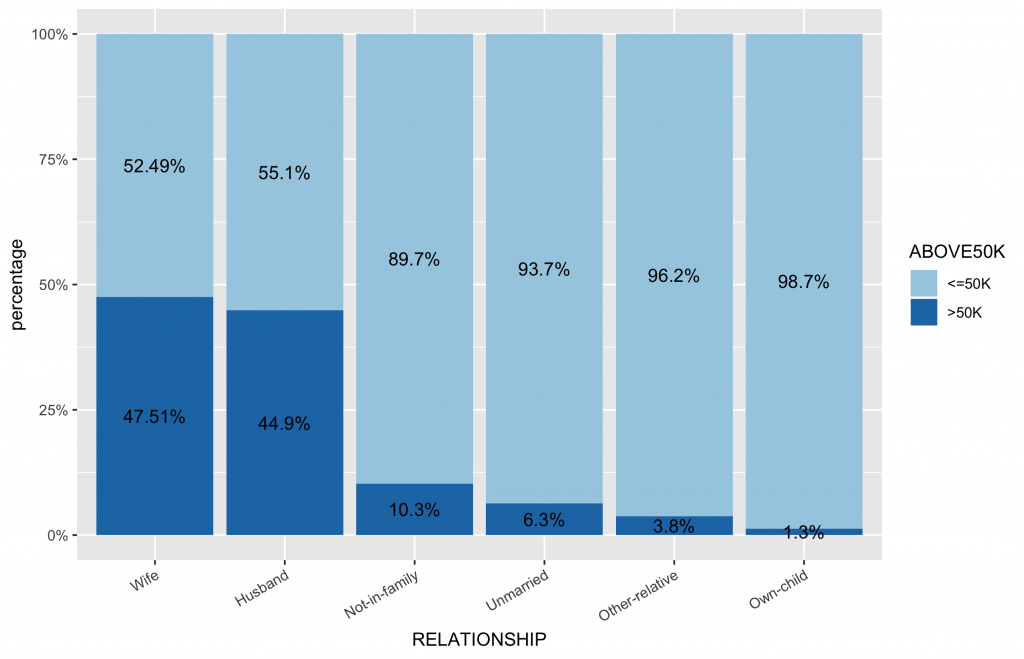
繪製同時一張圖呈現frequency與stacked bar目標類別水平的比例分佈圖。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
df3.summary df2.summary %>% group_by(RELATIONSHIP) %>% #因為繪圖資訊是先畫>50K,再畫 do( data.frame(with(data=., .[order(desc(ABOVE50K)),] )) ) %>% ungroup() %>% group_by(RELATIONSHIP) %>% mutate(pos = (cumsum(n) - (0.5 * n))) %>% as.data.frame() %>% ungroup() ggplot(data = df3.summary,mapping = aes(x = RELATIONSHIP, y = n, fill = ABOVE50K)) + geom_bar(stat = "identity") + geom_text(mapping = aes(y = pos, label = ratio), size = 3) + scale_fill_brewer(palette="Paired") + labs(title = "RELATIONSHIP VS ABOVE50K", x = "RELATIONSHIP", y = "Frequencies") + # Add Title and Labels theme(plot.title = element_text(hjust = 0.5), axis.text.x = element_text(angle = 30, hjust = 1)) # Change the appearance of the main title |
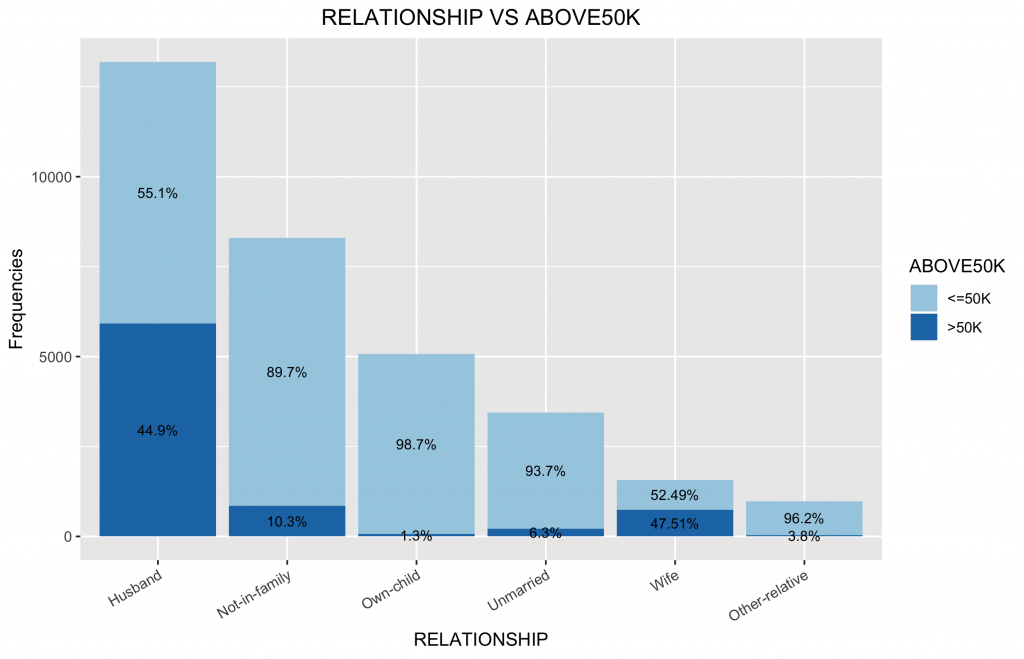
2-8. Race種族
基礎敘述統計
|
1 2 3 |
summary(inputData$RACE) # Amer-Indian-Eskimo Asian-Pac-Islander Black Other White # 311 1039 3124 271 27816 |
次數分配圖
|
1 2 3 4 5 6 |
inputData$RACE ggplot(data = inputData, aes(x = RACE, fill = ABOVE50K)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=3.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
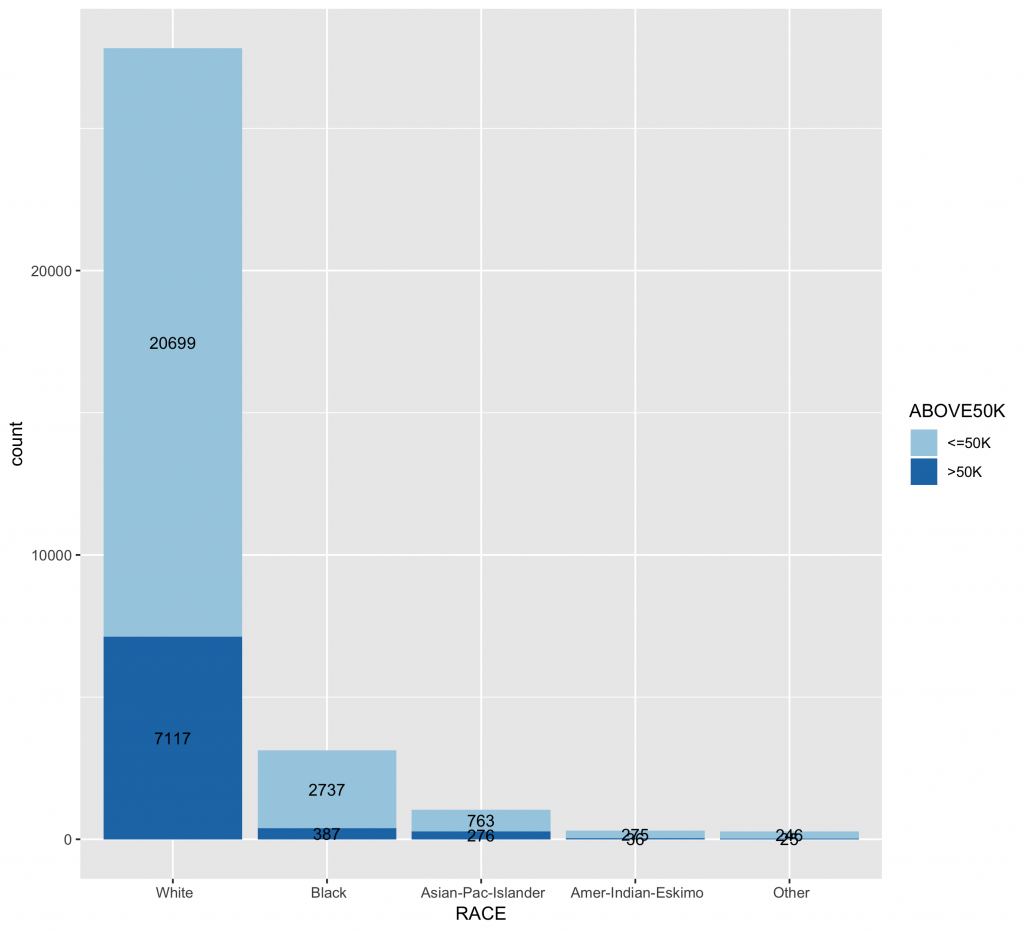
各類別水準值中目標變數分佈圖
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 首先,先計算類別變數中,不同類別水準值中的薪資水平分佈比例 df2 df2.summary df2 %>% group_by(RACE) %>% count(ABOVE50K) %>% mutate(ratio=scales::percent(n/sum(n))) %>% as.data.frame() %>% ungroup() # 依據ABOVE50K的比例排序,更可以看出哪些類別水準有較高ABOVE50K比例 ggplot(inputData, aes(x = forcats::fct_reorder(f = RACE, x = as.numeric(ABOVE50K), fun = mean, .desc = TRUE), fill = ABOVE50K)) + geom_bar(position = "fill") + geom_text(data=df2.summary, aes(y=n,label=ratio), position=position_fill(vjust=0.5)) + scale_y_continuous(labels = scales::percent) + scale_fill_brewer(palette="Paired") + labs(x = "RACE", y = "percentage") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
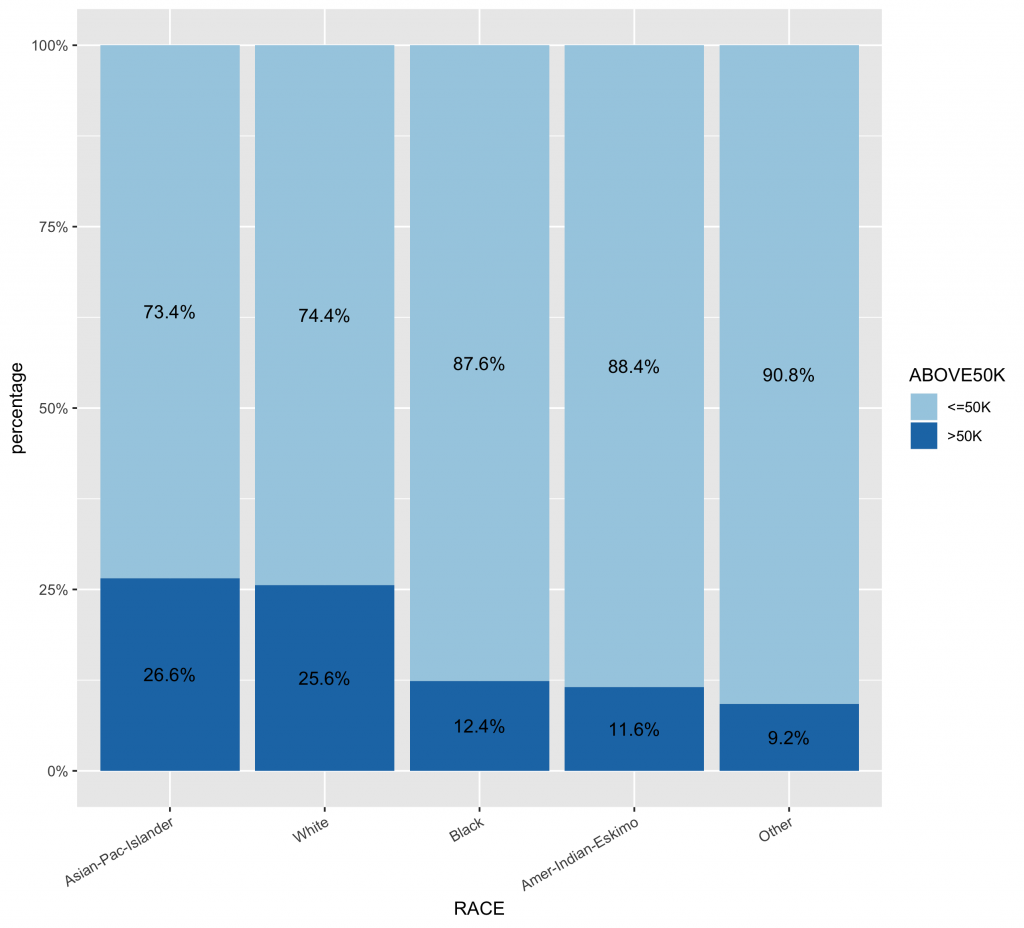
繪製同時一張圖呈現frequency與stacked bar目標類別水平的比例分佈圖。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
df3.summary df2.summary %>% group_by(RACE) %>% #因為繪圖資訊是先畫>50K,再畫 do( data.frame(with(data=., .[order(desc(ABOVE50K)),] )) ) %>% ungroup() %>% group_by(RACE) %>% mutate(pos = (cumsum(n) - (0.5 * n))) %>% as.data.frame() %>% ungroup() ggplot(data = df3.summary,mapping = aes(x = RACE, y = n, fill = ABOVE50K)) + geom_bar(stat = "identity") + geom_text(mapping = aes(y = pos, label = ratio), size = 3) + scale_fill_brewer(palette="Paired") + labs(title = "RACE VS ABOVE50K", x = "RACE", y = "Frequencies") + # Add Title and Labels theme(plot.title = element_text(hjust = 0.5), axis.text.x = element_text(angle = 30, hjust = 1)) # Change the appearance of the main title |
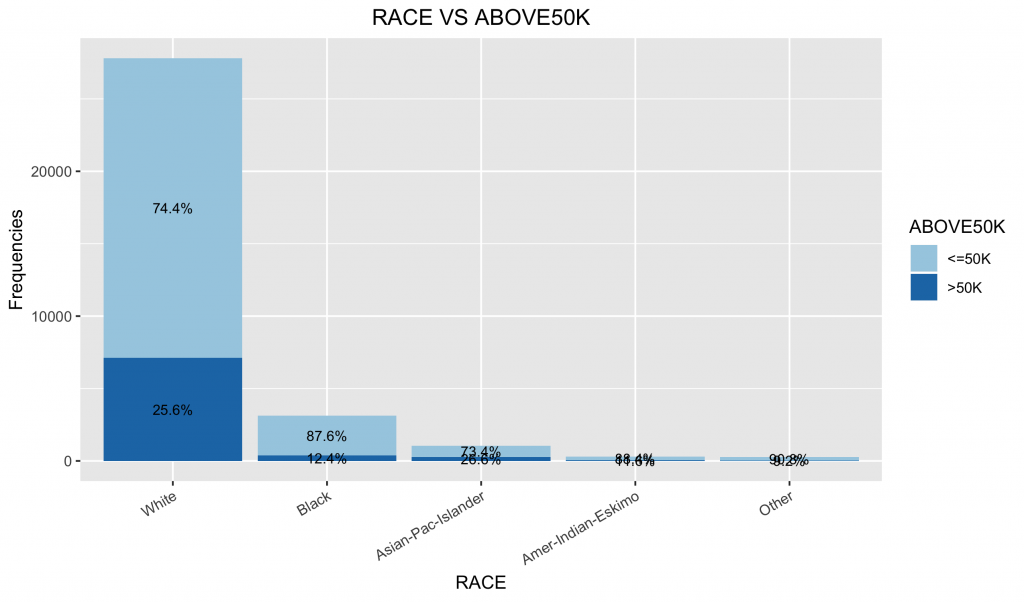
2-9. Sex 性別
基礎敘述統計
|
1 2 3 |
summary(inputData$SEX) # Female Male # 10771 21790 |
次數分配圖
|
1 2 3 4 5 |
inputData$SEX ggplot(data = inputData, aes(x = SEX, fill = ABOVE50K)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=3.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") |
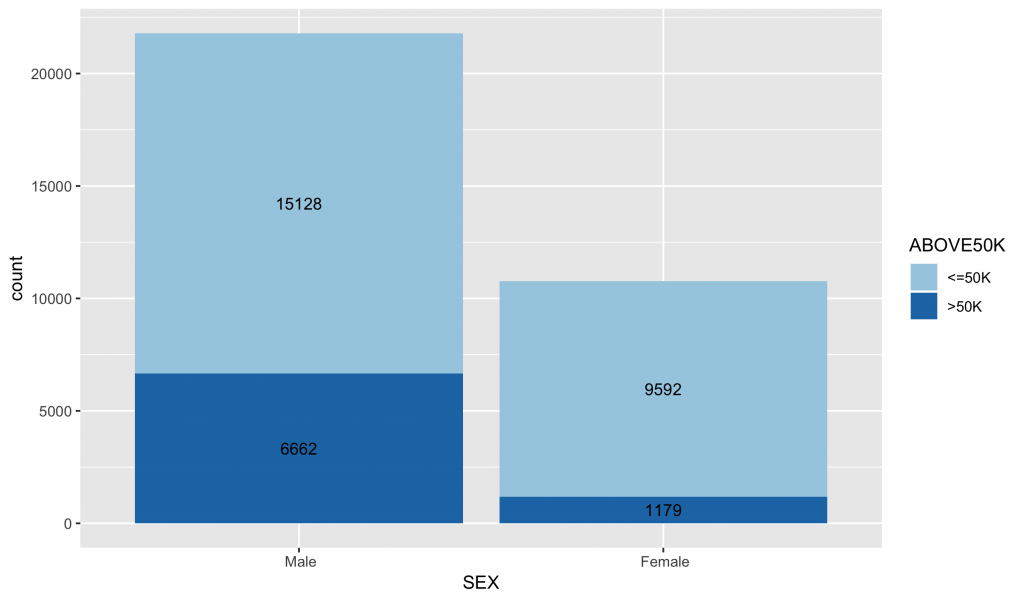
各類別水準值中目標變數分佈圖
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# 首先,先計算類別變數中,不同類別水準值中的薪資水平分佈比例 df2 df2.summary df2 %>% group_by(SEX) %>% count(ABOVE50K) %>% mutate(ratio=scales::percent(n/sum(n))) %>% as.data.frame() %>% ungroup() # 依據ABOVE50K的比例排序,更可以看出哪些類別水準有較高ABOVE50K比例 ggplot(inputData, aes(x = forcats::fct_reorder(f = SEX, x = as.numeric(ABOVE50K), fun = mean, .desc = TRUE), fill = ABOVE50K)) + geom_bar(position = "fill") + geom_text(data=df2.summary, aes(y=n,label=ratio), position=position_fill(vjust=0.5)) + scale_y_continuous(labels = scales::percent) + scale_fill_brewer(palette="Paired") + labs(x = "SEX", y = "percentage") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
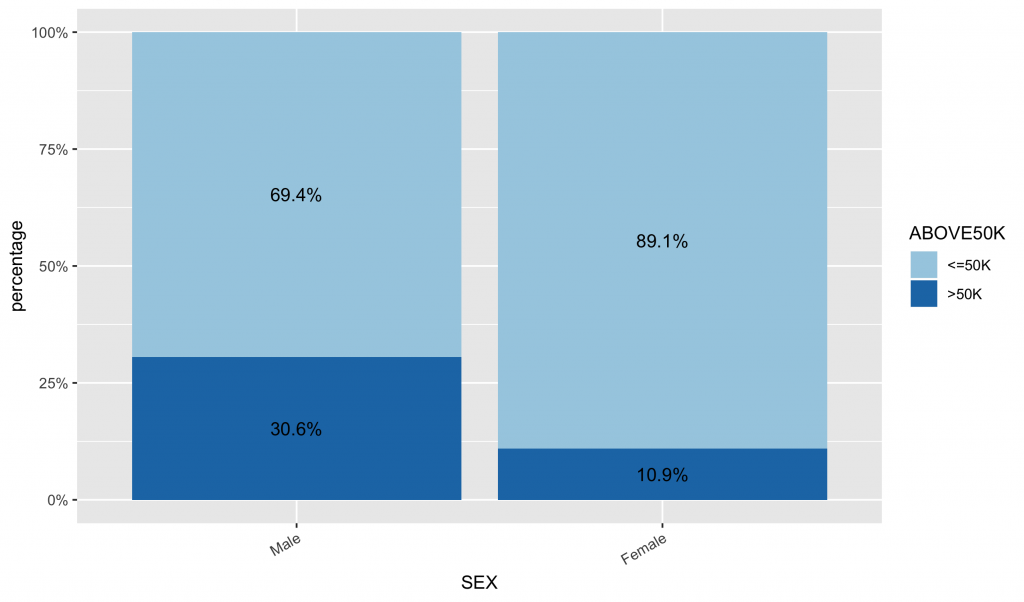
繪製同時一張圖呈現frequency與stacked bar目標類別水平的比例分佈圖。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
df3.summary df2.summary %>% group_by(SEX) %>% #因為繪圖資訊是先畫>50K,再畫 do( data.frame(with(data=., .[order(desc(ABOVE50K)),] )) ) %>% ungroup() %>% group_by(SEX) %>% mutate(pos = (cumsum(n) - (0.5 * n))) %>% as.data.frame() %>% ungroup() ggplot(data = df3.summary,mapping = aes(x = SEX, y = n, fill = ABOVE50K)) + geom_bar(stat = "identity") + geom_text(mapping = aes(y = pos, label = ratio), size = 3) + scale_fill_brewer(palette="Paired") + labs(title = "SEX VS ABOVE50K", x = "SEX", y = "Frequencies") + # Add Title and Labels theme(plot.title = element_text(hjust = 0.5), axis.text.x = element_text(angle = 30, hjust = 1)) # Change the appearance of the main title |
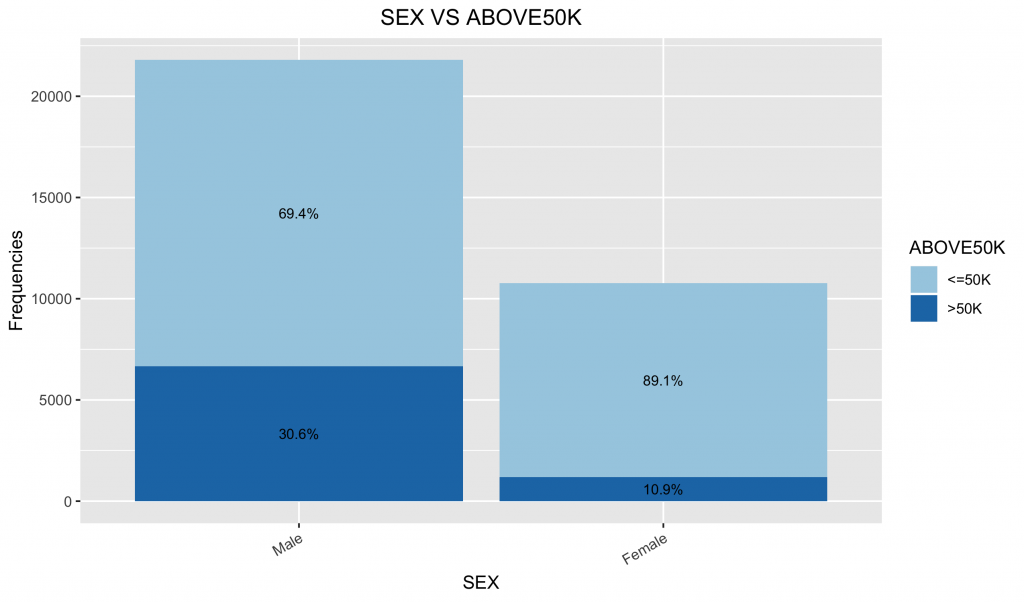
2-10. CapitalGain 資本獲利
基礎敘述統計
|
1 2 3 |
summary(inputData$CAPITALGAIN) # Min. 1st Qu. Median Mean 3rd Qu. Max. # 0 0 0 1078 0 99999 |
可以發現資料很右偏,至少有75%(第三個四分位數)的資料都是0。
次數分配圖
|
1 2 3 4 5 6 |
ggplot(data = inputData,mapping = aes(x = CAPITALGAIN, fill = ABOVE50K, group = ABOVE50K)) + geom_histogram(bins = 10,color = 'black',lwd =0.3, binwidth = 10000) + # default bins = 30 stat_bin(binwidth = 10000, geom = "text", color = "white", size = 3.5, mapping = aes(label = ..count.., group = ABOVE50K),position=position_stack(vjust=0.5)) + scale_fill_brewer(palette="Paired") + scale_x_continuous(breaks= seq(0,max(inputData$CAPITALGAIN), 10000)) |
我們可以觀察到,視覺化的資料極右偏,幾乎所有資料都是0
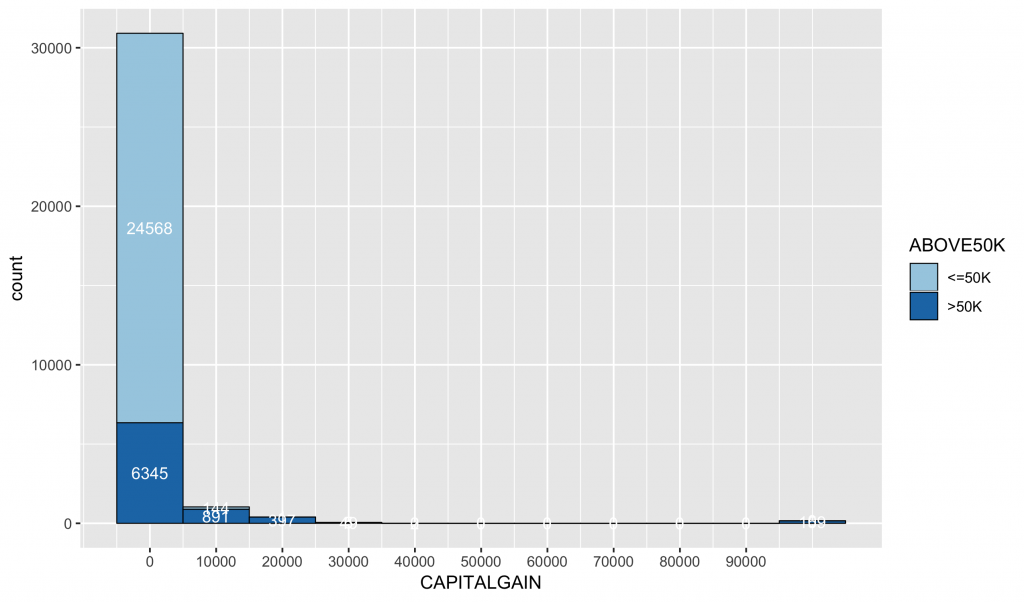
看一下capitalgain資料是0的比例:
|
1 2 |
sum(inputData$CAPITALGAIN == 0)/length(inputData$CAPITALGAIN) # [1] 0.9167102 |
2-11. Capital Loss 資本失利
基礎敘述統計
|
1 2 3 |
summary(inputData$CAPITALLOSS) # Min. 1st Qu. Median Mean 3rd Qu. Max. # 0.0 0.0 0.0 87.3 0.0 4356.0 |
次數分配圖
|
1 2 3 4 5 |
ggplot(data = inputData,mapping = aes(x = CAPITALLOSS, fill = ABOVE50K, group = ABOVE50K)) + geom_histogram(color = 'black',lwd =0.3, binwidth = 1000) + # default bins = 30 stat_bin(geom = "text", color = "white", size = 3.5, binwidth = 1000, mapping = aes(label = ..count.., group = ABOVE50K),position=position_stack(vjust=0.5)) + scale_fill_brewer(palette="Paired") |
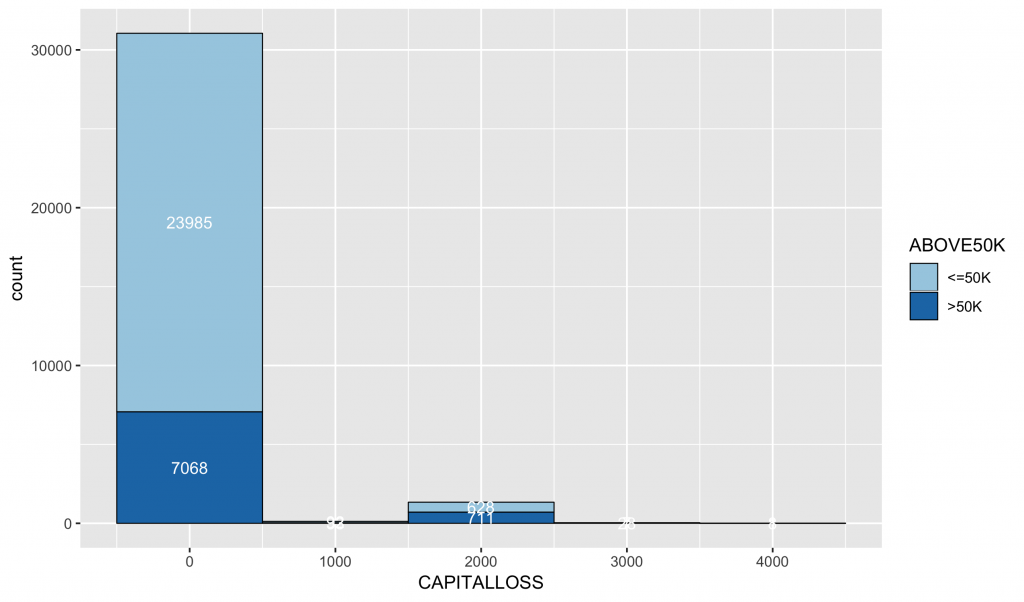
看一下CAPITALLOSS資料是0的比例:
|
1 2 |
sum(inputData$CAPITALLOSS == 0)/length(inputData$CAPITALLOSS) # [1] 0.9533491 |
2-12. HOURSPERWEEK
基礎敘述統計
|
1 2 3 |
summary(inputData$HOURSPERWEEK) # Min. 1st Qu. Median Mean 3rd Qu. Max. # 1.00 40.00 40.00 40.44 45.00 99.00 |
次數分配圖
|
1 2 3 4 5 |
ggplot(data = inputData,mapping = aes(x = HOURSPERWEEK, fill = ABOVE50K, group = ABOVE50K)) + geom_histogram(bins = 10, color = 'black',lwd =0.3) + # default bins = 30 stat_bin(geom = "text", color = "white", size = 3.5, bins = 10, mapping = aes(label = ..count.., group = ABOVE50K),position=position_stack(vjust=0.5)) + scale_fill_brewer(palette="Paired") |
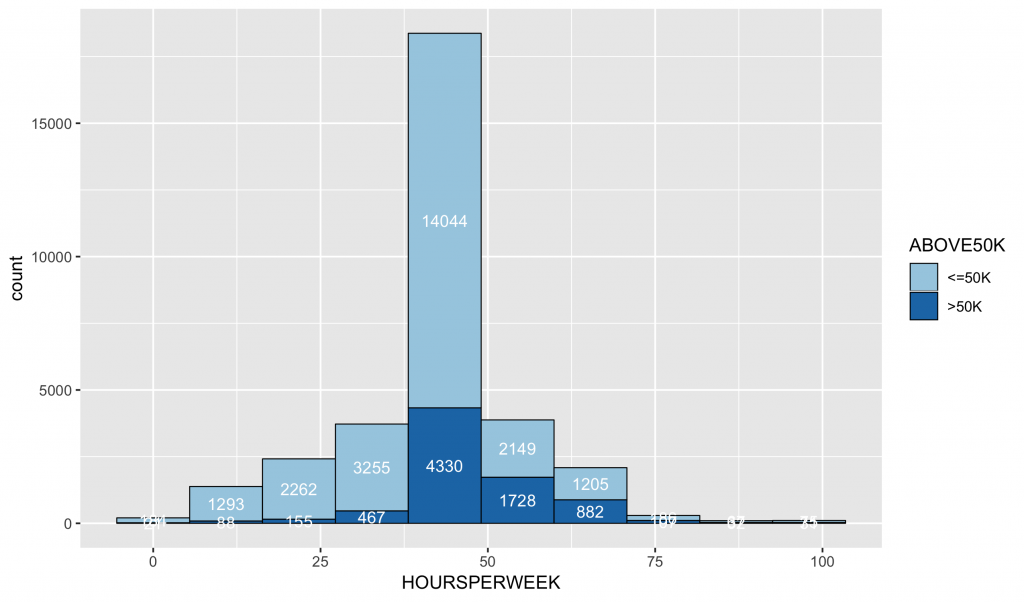
2-13. NATIVECOUNTRY 國籍
次數分配圖
|
1 2 3 4 5 6 |
inputData$NATIVECOUNTRY ggplot(data = inputData, aes(x = NATIVECOUNTRY, fill = ABOVE50K)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=3.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") + theme(axis.text.x = element_text(angle = 30, hjust = 1)) |
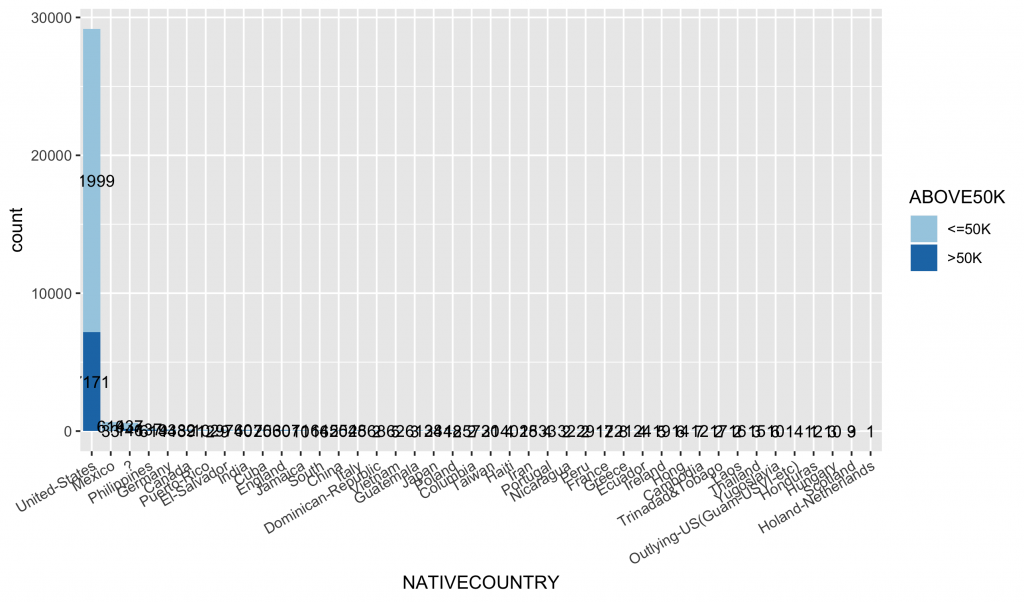
可以發現資料超偏,都集中在美國,因此不適合投入模型。
3. 資料前處理
3- 1. 類別水準值簡化
OCCUPATION的部分,因為水平值偏多,且沒有替代變數欄位,故我們考慮將此變數水平值簡化。我們將之簡化為以下幾群:
Blue-Collar, Professional, Sales, Service, and White-Collar, Other/Unknown。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# 先將?改命名成Unknown levels(inputData$OCCUPATION)[1] # 新增一個replacement水準值後的欄位: inputData$OCCUPATION_rep # (1) Craft-repair, Farming-fishing, Handlers-cleaners , Machine-op-inspct, Transport-moving => 合併成Blue-Collar inputData$OCCUPATION_rep inputData$OCCUPATION_rep inputData$OCCUPATION_rep inputData$OCCUPATION_rep inputData$OCCUPATION_rep # (2) Prof-specialty, => Professional inputData$OCCUPATION_rep # (3) Sales => Sales不變 # (4) Other-service, Priv-house-serv, Protective-serv, Tech-support, => Service inputData$OCCUPATION_rep inputData$OCCUPATION_rep inputData$OCCUPATION_rep inputData$OCCUPATION_rep # (5) Adm-clerical, Exec-managerial => 合併成White-Collar inputData$OCCUPATION_rep inputData$OCCUPATION_rep # (6) ?,Armed-Forces => Other/Unknown inputData$OCCUPATION_rep inputData$OCCUPATION_rep inputData$OCCUPATION_rep summary(inputData$OCCUPATION_rep) # Sales Blue-Collar Other/Unknown Professional Service White-Collar # 3650 10062 1852 4140 5021 7836 levels(inputData$OCCUPATION_rep) # [1] " Sales" "Blue-Collar" "Other/Unknown" "Professional" "Service" "White-Collar" |
3-2. (optional)產生類別變數的WOE值(本分析不會執行此段程式碼)
|
1 2 3 4 5 6 7 |
# 這是一個選擇性的步驟,我們在本分析不會執行 # factor_vars # not run # for(factor_var in factor_vars){ # inputData[[factor_var]] # } |
4. 產生訓練資料集與測試資料集
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
# 產生訓練資料集 input_ones input_zeros set.seed(100) input_ones_training_row input_zeros_training_row training_ones training_zeros trainingData # 產生測試資料集 test_ones test_zeros testData |
5. 計算IV值,篩選變數
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
# 我們會使用套件中的函數smbinning::smbinning,來將連續變數切割為類別變數 library(smbinning) # 將連續型變數和類別型變數分開 # 記得加入"OCCUPATION_rep" factor_vars continuous_vars # 建立一個變數IV值表格 : numeric(參數要放變數行數) iv_df # 計算類別變數的IV值 for(factor_var in factor_vars){ smb if(class(smb) != "character"){ iv_df[iv_df$VARS == factor_var,"IV"] } } # 計算連續變數的IV值 for(continuous_var in continuous_vars){ smb if(class(smb) != "character"){ iv_df[iv_df$VARS == continuous_var,"IV"] } } # 將變數依據IV值高低排列 iv_df iv_df # VARS IV # 6 RELATIONSHIP 1.5435 # 3 MARITALSTATUS 1.3195 # 10 AGE 1.1815 # 12 EDUCATIONNUM 0.7169 # 14 CAPITALGAIN 0.6849 # 13 HOURSPERWEEK 0.4592 # 5 OCCUPATION_rep 0.3594 # 8 SEX 0.3127 # 1 WORKCLASS 0.1673 # 7 RACE 0.0634 # 2 EDUCATION 0.0000 # 4 OCCUPATION 0.0000 # 9 NATIVECOUNTRY 0.0000 # 11 FNLWGT 0.0000 # 15 CAPITALLOSS 0.0000 |
關於IV Table的部分,我們可以得出以下資訊:
- 根據經驗,IV>=0.3即表示該預測變數與目標變數有較強的關係。
- 類別變數IV=0表示類別水準值過多。
- EDUCATION: 可以使用IV值較高的EDUCATIONNUM代替。
- NATIVECOUNTRY:如我們一開始在資料探勘時所見,絕大多數資料皆為United States,因此不予進一步討論。
- 連續變數IV=0表示沒有顯著的切點存在。
- FNLWGT:一開始為簡化分析,即不考慮納入模型分析。
- CAPITALLOSS: 因為該特徵資料分佈極偏,故不納入進一步模型分析。
- 從IV表數值,我們決定初步篩選出變數RELATIONSHIP, MARITALSTATUS, AGE, EDUCATIONNUM, CAPITALGAIN, OCCUPATION_rep進行模型分析。
Logistic Regression Modeling 羅吉斯回歸建模 part2 的部分請參考: 羅吉斯回歸 – part2 模型建置、診斷與比較。
更多模型建置筆記連結:
- Logistic Regression 羅吉斯迴歸 | part2 – 模型建置、診斷與比較 | R語言
- Linear Regression | 線性迴歸模型 | using AirQuality Dataset
- Regularized Regression | 正規化迴歸 – Ridge, Lasso, Elastic Net | R語言
- Decision Tree 決策樹 | CART, Conditional Inference Tree, Random Forest
- Regression Tree | 迴歸樹, Bagging, Bootstrap Aggregation | R語言
- Random Forests 隨機森林 | randomForest, ranger, h2o | R語言
- Gradient Boosting Machines GBM | gbm, xgboost, h2o | R語言
- Hierarchical Clustering 階層式分群 | Clustering 資料分群 | R統計
- Partitional Clustering | 切割式分群 | Kmeans, Kmedoid | Clustering 資料分群
- Principal Components Analysis (PCA) | 主成份分析 | R 統計
參考: