



本篇筆記主要介紹簡單基礎 Summarize categorical variables 摘要類別變數的方法。包括類別次數或百分比交叉表/聯列表,以及將結果視覺化的長條圖(bar chart)。有效熟悉類別變數資料探索方法並熟悉基本的R繪圖函數。
「 Summarize Categorical Variables 類別變數摘要」學習筆記重點
- 目標變數(Dependent Variable) : Categorical (本範例將Survived設定為欲探討的目標變數)
- 預測變數(Independent Variable) : Categorical
- 使用資料集:1912年4月14日鐵達尼號沈船資料。我們使用titanic_train資料中共891筆乘客資料來示範如何摘要類別變數。
學習重點包括:
- 類別變數摘要table(表格、交叉表、列聯表)
- 類別變數資訊基礎視覺化
- 類別變數資訊進階視覺化(ggplot2)
資料集載入與檢視
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
library(titanic) data("titanic_train") df # View(df) head(df) # PassengerId Survived Pclass Name Sex Age SibSp Parch # 1 1 0 3 Braund, Mr. Owen Harris male 22 1 0 # 2 2 1 1 Cumings, Mrs. John Bradley (Florence Briggs Thayer) female 38 1 0 # 3 3 1 3 Heikkinen, Miss. Laina female 26 0 0 # 4 4 1 1 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35 1 0 # 5 5 0 3 Allen, Mr. William Henry male 35 0 0 # 6 6 0 3 Moran, Mr. James male NA 0 0 # Ticket Fare Cabin Embarked # 1 A/5 21171 7.2500 S # 2 PC 17599 71.2833 C85 C # 3 STON/O2. 3101282 7.9250 S # 4 113803 53.1000 C123 S # 5 373450 8.0500 S # 6 330877 8.4583 Q |
檢視資料結構
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
str(df) # 'data.frame': 891 obs. of 12 variables: # $ PassengerId: int 1 2 3 4 5 6 7 8 9 10 ... # $ Survived : int 0 1 1 1 0 0 0 0 1 1 ... # $ Pclass : int 3 1 3 1 3 3 1 3 3 2 ... # $ Name : chr "Braund, Mr. Owen Harris" "Cumings, Mrs. John Bradley (Florence Briggs Thayer)" "Heikkinen, Miss. Laina" "Futrelle, Mrs. Jacques Heath (Lily May Peel)" ... # $ Sex : chr "male" "female" "female" "female" ... # $ Age : num 22 38 26 35 35 NA 54 2 27 14 ... # $ SibSp : int 1 1 0 1 0 0 0 3 0 1 ... # $ Parch : int 0 0 0 0 0 0 0 1 2 0 ... # $ Ticket : chr "A/5 21171" "PC 17599" "STON/O2. 3101282" "113803" ... # $ Fare : num 7.25 71.28 7.92 53.1 8.05 ... # $ Cabin : chr "" "C85" "" "C123" ... # $ Embarked : chr "S" "C" "S" "S" ... |
為了後續類別變數間分析,我們將以下變數進行型態轉換:
(1) Survived(是否生還)將原本整數(0,1)轉換為factor的levels(“Died”, “Survived”)
(2)Pclass(座艙等級)將原本整數(1,2,3)轉換為factor的levels(‘First’,’Second’,’Third’)
|
1 2 3 4 5 |
# enable objects in the database can be accessed by simply giving their names. attach(df) # 不用呼叫database,直接呼叫variable's name Survived Pclass |
1. 類別變數摘要table(表格、交叉表、列聯表)
類別變數次數分佈: table()
|
1 2 3 4 5 6 |
SurT SurT # Survived # Died Survived # 549 342 |
如果要加上加總項: addmargins()
|
1 2 3 4 5 |
addmargins(SurT) # Survived # Died Survived Sum # 549 342 891 |
如果要計算table裡面的比例: prop.table()
|
1 2 3 4 5 |
prop.table(SurT) # Survived # Died Survived # 0.616 0.384 |
如果要調整小數位數: 可以使用round()
|
1 2 3 4 5 |
round(prop.table(SurT), digits = 2) # Survived # Died Survived # 0.62 0.38 |
如果要進一步將Survival生存依據Class座艙等級區分,我們會需要交叉表(Cross Table)或列聯表(Contingency Table)。
|
1 2 3 4 5 6 7 |
cross cross # Pclass # Survived First Second Third # Died 80 97 372 # Survived 136 87 119 |
亦可使用addmargins(),替表格加上列和行的加總項
|
1 2 3 4 5 6 |
addmargins(cross) # Pclass # Survived First Second Third Sum # Died 80 97 372 549 # Survived 136 87 119 342 # Sum 216 184 491 891 |
並可以透過addmargins()中的參數margin=1,2來調整是否計算加總列/行。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 只要加總行: addmargins(cross, margin = 1) # Pclass # Survived First Second Third # Died 80 97 372 # Survived 136 87 119 # Sum 216 184 491 # 只要加總列: addmargins(cross, margin = 2) # Pclass # Survived First Second Third Sum # Died 80 97 372 549 # Survived 136 87 119 342 |
如果要產生列聯表的機率數值,使用prop.table()。
當我們想知道不同座艙等級(Pclass)乘客的生存比例(Survived)是否有差異時,可以計算以下列聯表機率:
|
1 2 3 4 5 6 7 |
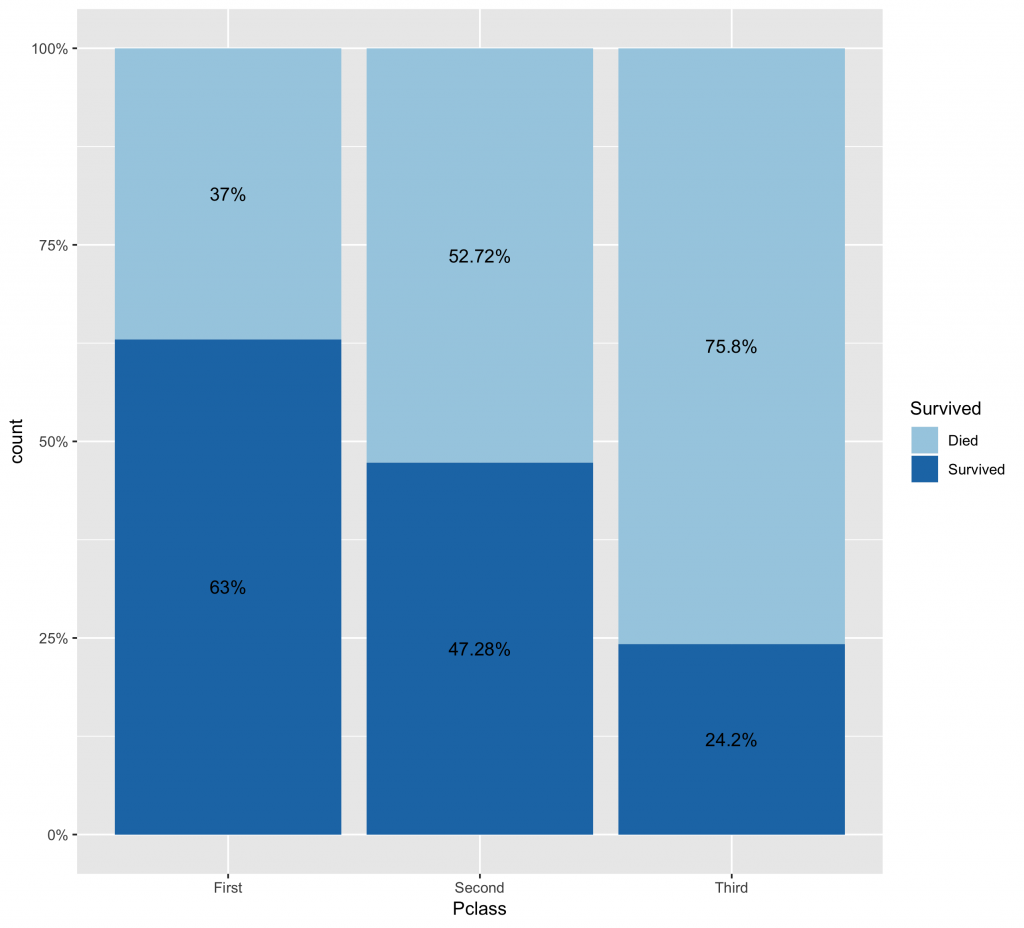
#計算column的百分比分佈。如果要計算row的百分比分佈,margin=1 prop.table(cross, margin = 2) # Pclass # Survived First Second Third # Died 0.370 0.527 0.758 # Survived 0.630 0.473 0.242 |
2. 類別變數資訊進階視覺化
如果希望進一步將這個列聯表機率資訊視覺化: 使用barplot()
|
1 2 3 |
barplot(cross,xlab = 'Class',ylab = 'Frequency',main = "Survival by Class",col = c('darkblue','lightcyan'), legend.text = rownames(cross), #圖示說明各顏色所代表類別 args.legend = list(x = 'topleft')) |
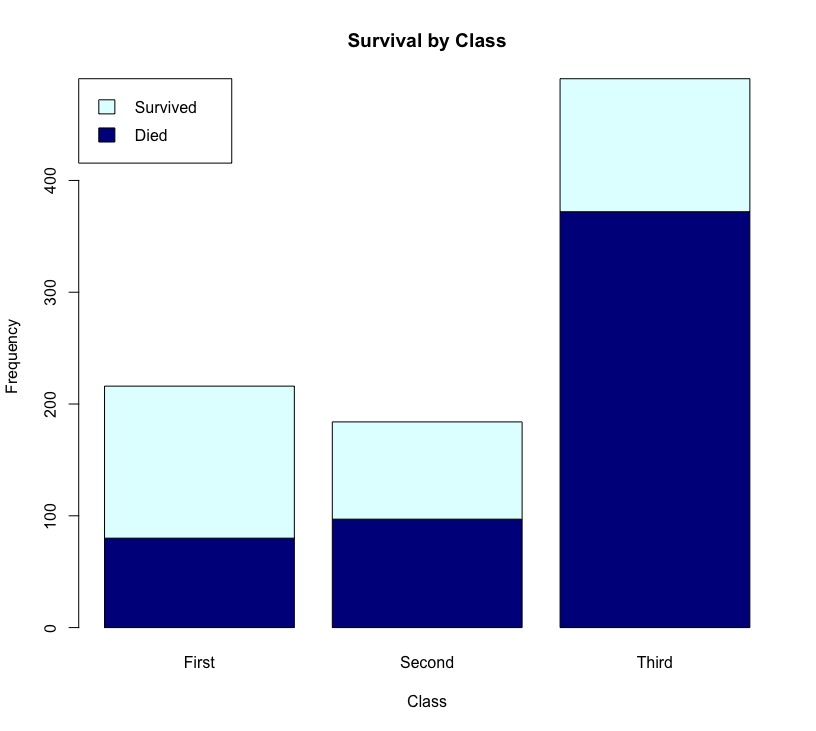
但只有frequencoes資訊是比較難比較出個座艙等級的survival比例變化。這時會用percentage來觀察,只需將cross改就prop.table(cross)。只是barplot()無法標上百分比資訊於圖上。
|
1 2 3 |
barplot(prop.table(cross,2),xlab = 'Class',ylab = 'Frequency',main = "Survival by Class",col = c('darkblue','lightcyan'), legend.text = rownames(cross), #圖示說明各顏色所代表類別 args.legend = list(x = 'topleft')) |
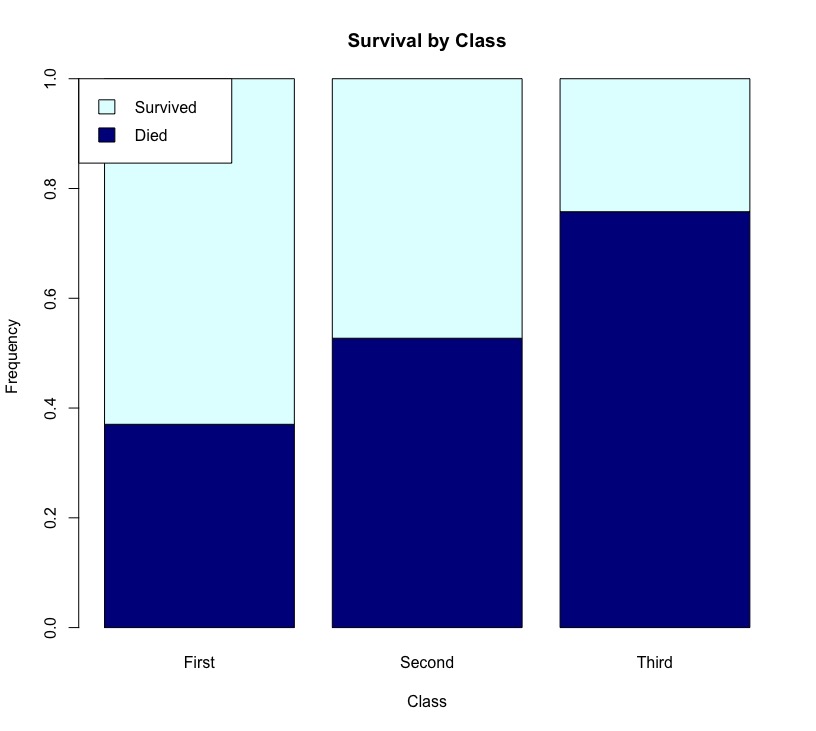
如果想將stacked bar改變成並排的clustered bar,則須將參數設定為beside = True。
|
1 2 3 4 |
barplot(prop.table(cross,2),xlab = 'Class',ylab = 'Frequency',main = "Survival by Class",col = c('darkblue','lightcyan'), legend.text = rownames(cross), #圖示說明各顏色所代表類別 beside = TRUE, args.legend = list(x = 'topleft')) |
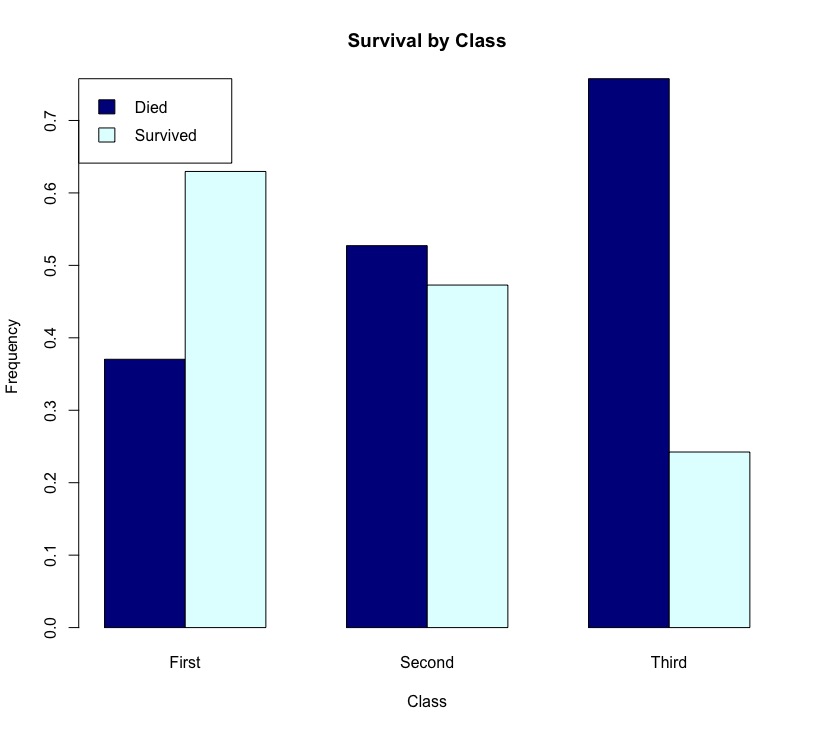
3. 類別變數資訊進階視覺化(ggplot2)
為了解決label的問題,我們改使用ggplot2套件來繪製。先將df中factor生成。
|
1 2 |
df$Survived df$Pclass |
Frequencies次數圖
|
1 2 3 4 |
ggplot(data = df, aes(x = Pclass, fill = Survived)) + geom_bar() + geom_text(stat = "count", aes(label=..count..),size=4.5,position = position_stack(vjust = 0.5)) + scale_fill_brewer(palette="Paired") |
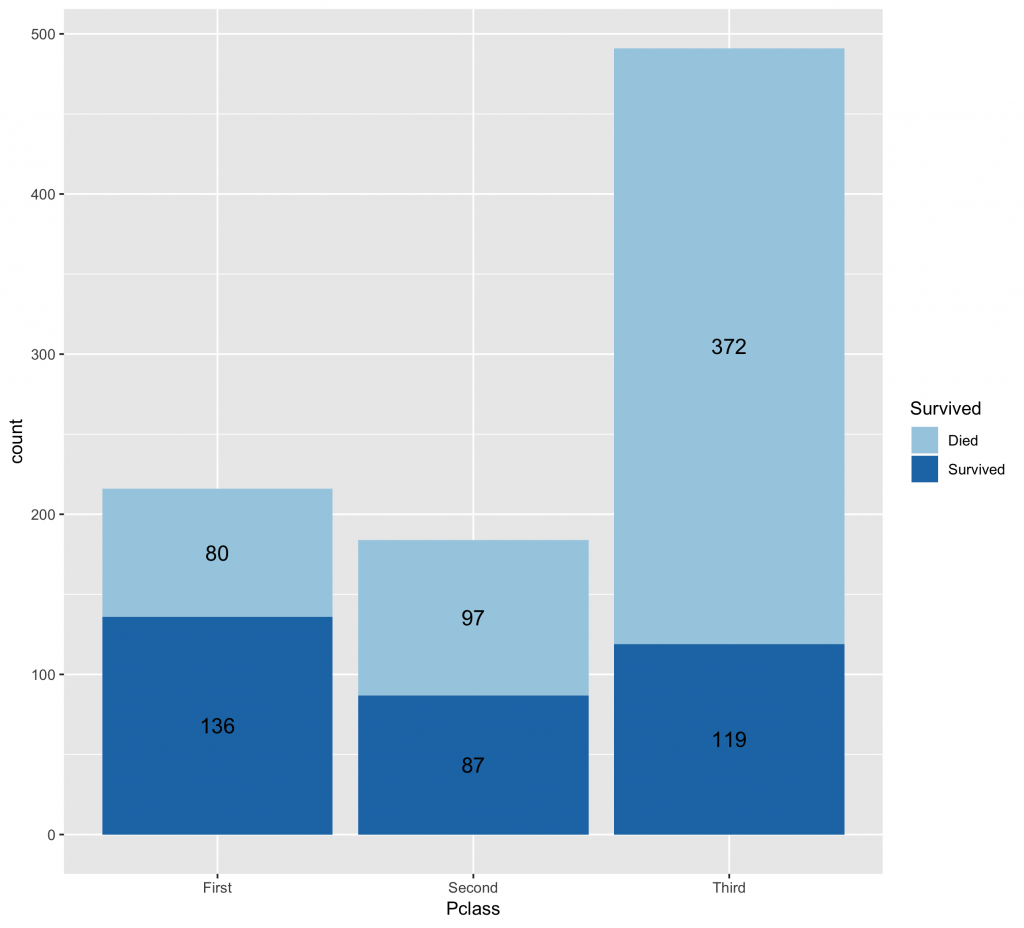
Percentage百分比圖
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
# 首先,先計算根據不同Pclass所計算的生存比率分佈 df.summary df %>% group_by(Pclass) %>% count(Survived) %>% mutate(ratio=scales::percent(n/sum(n))) %>% ungroup() # 將不同的Pclass的機率分佈標記上 ggplot(df, aes(x = Pclass, fill = Survived)) + geom_bar(position = "fill") + geom_text(data=df.summary, aes(y=n,label=ratio), position=position_fill(vjust=0.5)) + scale_y_continuous(labels = scales::percent) + scale_fill_brewer(palette="Paired") |
更多資料視覺化筆記連結: