



RFM Model 是個簡易客戶分群的模型,依據消費者的Recency, Frequency, Monetary維度資訊來快速檢視客群組成,並能幫助行銷者快速評估最適化的CRM方案,極大化投資報酬率。比如說,若能知道各客群歷史回應率,就能預測不同客群的行銷效果(預期回應人數與報酬率),並客製化CRM行銷策略。
RFM Model
在精準行銷的時代,行銷者需要評估資源(或預算)如何有效的分配給對的目標受眾輪廓,最大化投資報酬率。主要需評估的問題包括兩個面向:
- Customer Segmentation
- 如何有效區隔消費者,並找出各消費者分群的特色如:高貢獻度、高往來程度、以及高回應率等。
- CRM strategies
- 根據消費者所屬分群特性,挑選合適的目標受眾進行行銷,以獲取最大報酬率。
RFM模型則是一個簡單卻有效的顧客分析模型,能幫助我們解決以上兩個問題。其中RFM分別代表:
- R – Recency : 消費者最後一次購買距今天數。
- F – Frequency: 消費者購買頻率。
- M – Monetary: 消費者平均花費金額(每一次購物/訂單結帳)。
雖然RFM模型在部分統計分析軟體中有現成快速套用的RFM功能節點(ex: IBM SPSS RFM),在R裡面並沒有簡易現成的套件能快速套用。故本學習筆記將說明如何使用R語言進行RFM分析。
Data Explore
我們使用CDNOW dataset (1/10th sample),下載連結。
|
1 2 3 |
# read CDNOW_SAMPLE.txt rawdf head(rawdf) |
|
1 2 3 4 5 6 7 8 |
## V1 V2 V3 V4 V5 ## 1 4 1 19970101 2 29.33 ## 2 4 1 19970118 2 29.73 ## 3 4 1 19970802 1 14.96 ## 4 4 1 19971212 2 26.48 ## 5 21 2 19970101 3 63.34 ## 6 21 2 19970113 1 11.77 |
|
1 2 3 4 5 6 7 |
# select columns of interest : df # rename columns' names names(df) # transfer column Date type from int type to date type df$Date head(df) |
|
1 2 3 4 5 6 7 8 |
## ID Date Amount ## 1 4 1997-01-01 29.33 ## 2 4 1997-01-18 29.73 ## 3 4 1997-08-02 14.96 ## 4 4 1997-12-12 26.48 ## 5 21 1997-01-01 63.34 ## 6 21 1997-01-13 11.77 |
|
1 2 |
# see total row&column number dim(df) |
|
1 2 |
## [1] 6919 3 |
|
1 2 3 |
# count the number of distinct ID uid dim(uid) |
|
1 2 |
## [1] 2357 3 |
我們可以知道獨立用戶ID數為2357,交易比數共為6919。
Segment the Customers into RFM Cells
根據剛剛載入的資料,我們可以依據R,F,M三個維度將客戶分群到各個RFM Cell。
而通常,我們會幫客戶在每個維度給予1~5級的評分(維度bin數量可以根據情境調整),分數越高表示在該維度程度越高。
且根據過去經驗來說,Recency是高回應率的主要關鍵影響因素(x100),Frequency是次要影響因素(x10),最後才是Monetary(x1)。被分類到同一個RFM Cell的客戶分數會是相同的。分數“531″代表著該客戶在Recency得到5分,Frequency得到3分,Monetary則為1分。
在每一維度進行客戶切群(分箱,Binning)的方法有兩種:一種是Nested Binning巢狀法,另一種是Independent Binning獨立法。
- Nested Binning 巢狀法:先將客群在Recency維度切成若干等分(aliquots),然後從每組Recency等分中再依據Frequency切割成若干等份,Monetary亦然。此法的好處是,每一群RFM Cell的人數會差不多,但缺點就是不同Recency分群下的Frequency和Monetary的意義就無法比較,分數相同,但意義不同。
- Independent Binning 獨立法:則是獨立將客戶在各維度進行等分切群,這樣的好處就是,同樣RFM分數的意義是相同的,但缺點就是每群RFM Cell中的人數大小會有差距。
更多有關維度切bin(分箱)方法的優缺點比較(pros & cons)可參考此連結。
為了讓每一群RFM Cell可以相互比較,本學習筆記將先以Independent法,依據各維度分佈來決定bin的切點(breaks)。
Calculate the Recency, Frequency, and Monetary
為了進行RFM分析,我們需要進一步處理加工CDNOW Sample資料集,分為以下幾個步驟:
- group by unique customer ID
- 計算每個ID的Recency: 計算最新的一筆交易距離今日或其他指定日期的天數。
- 計算每個ID的Frequency: 計算每個人的總交易次數。
- 計算每個ID的Monetary: 計算每個人的交易金額加總除上總交易次數,即平均每筆交易的金額。
首先,先限制分析資料的時間區間如下:
|
1 2 |
startDate endDate |
group by 每個獨立ID計算以上時間區間的R,F,M值。其中Recency是最近一次交易距離endDate(1998-07-01)的天數。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
library(dplyr) library(magrittr) df.1 df %>% filter(Date >= startDate & Date % group_by(ID) %>% summarise( MaxTransDate = max(Date), Amount = sum(Amount), Recency = as.numeric(endDate - MaxTransDate), Frequency = n(), Monetary = Amount/Frequency ) %>% ungroup() %>% as.data.frame() head(df.1) |
|
1 2 3 4 5 6 7 8 |
## ID MaxTransDate Amount Recency Frequency Monetary ## 1 4 1997-12-12 100.50 201 4 25.125 ## 2 18 1997-01-04 14.96 543 1 14.960 ## 3 21 1997-01-13 75.11 534 2 37.555 ## 4 50 1997-01-01 6.79 546 1 6.790 ## 5 60 1997-02-01 21.75 515 1 21.750 ## 6 71 1997-01-01 13.97 546 1 13.970 |
Independent RFM Scoring
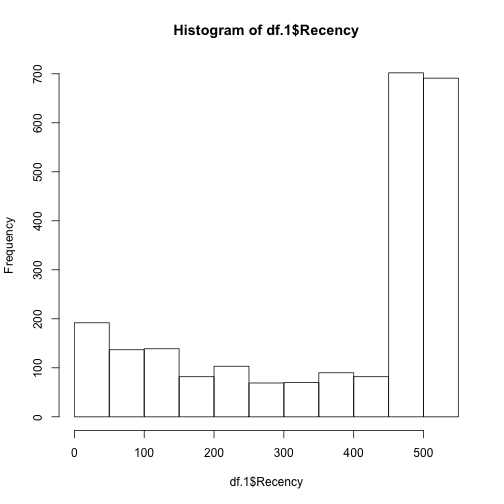
檢視Recency維度的分佈資訊。
|
1 |
quantile(df.1$Recency, probs = seq(0,1,by = 0.2)) |
|
1 2 3 |
## 0% 20% 40% 60% 80% 100% ## 1 153 443 487 513 546 |
|
1 |
hist(df.1$Recency) |
|
1 |
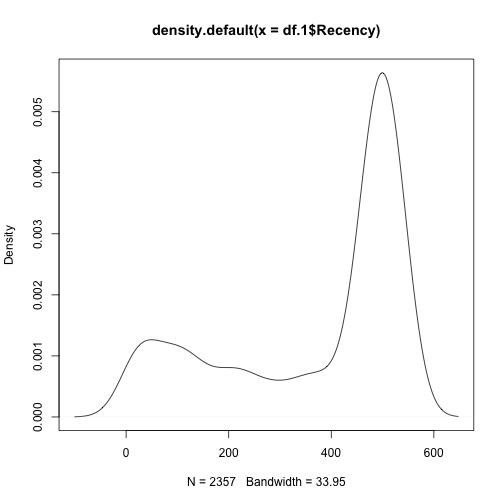
plot(density(df.1$Recency)) |
Recency binning
依據Recency維度的百分位數(quantile)進行切群(binning),每間隔20%百分位數切一等份。
|
1 2 3 4 |
labels = c(5,4,3,2,1) df.1$R_Score head(df.1) |
|
1 2 3 4 5 6 7 8 |
## ID MaxTransDate Amount Recency Frequency Monetary R_Score ## 1 4 1997-12-12 100.50 201 4 25.125 4 ## 2 18 1997-01-04 14.96 543 1 14.960 1 ## 3 21 1997-01-13 75.11 534 2 37.555 1 ## 4 50 1997-01-01 6.79 546 1 6.790 1 ## 5 60 1997-02-01 21.75 515 1 21.750 1 ## 6 71 1997-01-01 13.97 546 1 13.970 1 |
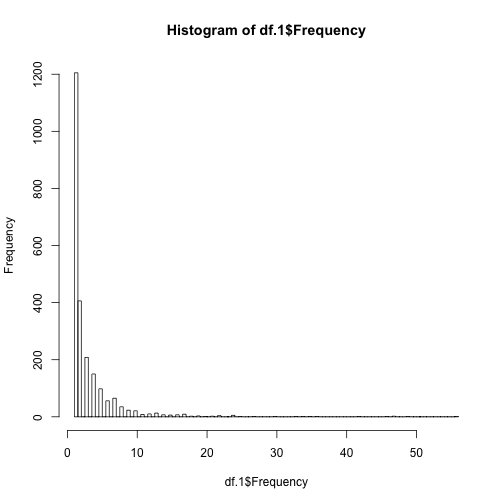
檢視Frequency維度的分佈資訊。
可以發現前80%百分位數都集中在1,2,3,4等數值。
|
1 |
quantile(df.1$Frequency, probs = seq(0,1,by = 0.2)) |
|
1 2 3 |
## 0% 20% 40% 60% 80% 100% ## 1 1 1 2 4 56 |
|
1 |
summary(df.1$Frequency) |
|
1 2 3 |
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 1.000 1.000 1.000 2.936 3.000 56.000 |
|
1 |
hist(df.1$Frequency, breaks = 100) |
|
1 |
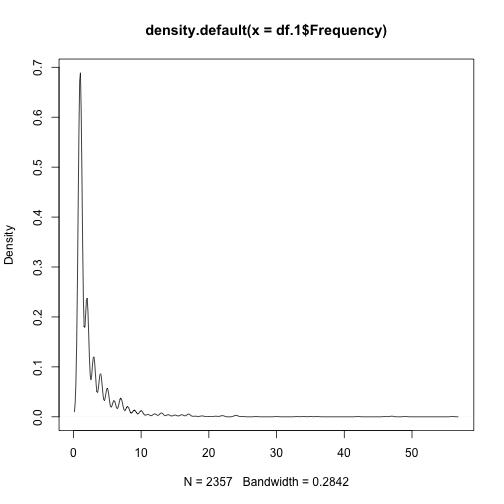
plot(density(df.1$Frequency)) |
Frequency binning
Frequency的部分則使用指定的1,2,3,4,5+的bin區間來進行分箱。
|
1 2 3 4 |
labels.freq = c(1,2,3,4,5) df.1$F_Score head(df.1) |
|
1 2 3 4 5 6 7 8 |
## ID MaxTransDate Amount Recency Frequency Monetary R_Score F_Score ## 1 4 1997-12-12 100.50 201 4 25.125 4 4 ## 2 18 1997-01-04 14.96 543 1 14.960 1 1 ## 3 21 1997-01-13 75.11 534 2 37.555 1 2 ## 4 50 1997-01-01 6.79 546 1 6.790 1 1 ## 5 60 1997-02-01 21.75 515 1 21.750 1 1 ## 6 71 1997-01-01 13.97 546 1 13.970 1 1 |
|
1 |
table(df.1$F_Score) |
|
1 2 3 4 |
## ## 1 2 3 4 5 ## 1205 406 208 150 388 |
檢視Monetary維度的分佈資訊。
|
1 |
quantile(df.1$Monetary, probs = seq(0,1,by = 0.2)) |
|
1 2 3 |
## 0% 20% 40% 60% 80% 100% ## 0.00000 14.37000 20.40800 29.33098 43.08773 506.97000 |
|
1 |
summary(df.1$Monetary) |
|
1 2 3 |
## Min. 1st Qu. Median Mean 3rd Qu. Max. ## 0.00 15.24 24.99 32.44 38.51 506.97 |
|
1 |
hist(df.1$Monetary,200) |
|
1 |
plot(density(df.1$Monetary)) |
Monetary binning
Monetary維度則使用百分位數法來進行分箱。
|
1 2 3 4 |
labels.mon = c(1,2,3,4,5) df.1$M_Score table(df.1$M_Score) |
|
1 2 3 4 |
## ## 1 2 3 4 5 ## 487 456 471 471 472 |
|
1 |
head(df.1) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
## ID MaxTransDate Amount Recency Frequency Monetary R_Score F_Score ## 1 4 1997-12-12 100.50 201 4 25.125 4 4 ## 2 18 1997-01-04 14.96 543 1 14.960 1 1 ## 3 21 1997-01-13 75.11 534 2 37.555 1 2 ## 4 50 1997-01-01 6.79 546 1 6.790 1 1 ## 5 60 1997-02-01 21.75 515 1 21.750 1 1 ## 6 71 1997-01-01 13.97 546 1 13.970 1 1 ## M_Score ## 1 3 ## 2 2 ## 3 4 ## 4 1 ## 5 3 ## 6 1 |
計算total score
將R_Score, F_Score, M_Score三個數值合併為新的三位數值。
|
1 2 |
df.1$Total_Score head(df.1) |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
## ID MaxTransDate Amount Recency Frequency Monetary R_Score F_Score ## 1 4 1997-12-12 100.50 201 4 25.125 4 4 ## 2 18 1997-01-04 14.96 543 1 14.960 1 1 ## 3 21 1997-01-13 75.11 534 2 37.555 1 2 ## 4 50 1997-01-01 6.79 546 1 6.790 1 1 ## 5 60 1997-02-01 21.75 515 1 21.750 1 1 ## 6 71 1997-01-01 13.97 546 1 13.970 1 1 ## M_Score Total_Score ## 1 3 443 ## 2 2 112 ## 3 4 124 ## 4 1 111 ## 5 3 113 ## 6 1 111 |
查看每一個RFM Cell的人數分佈
R_Score和M_Score兩維度交叉表。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
library(ggplot2) # plot data df.1 %>% mutate(R_Score = as.factor(R_Score), F_Score = as.factor(F_Score)) %>% group_by(R_Score, F_Score) %>% summarise(value = n()) %>% ungroup() %>% ggplot(aes(R_Score, F_Score)) + geom_tile(aes(fill = value), col = "black") + geom_text(aes(label = round(value, 1))) + scale_fill_gradient2() + theme(panel.background = element_blank(), panel.grid.major = element_blank(), panel.grid.minor = element_blank(), text = element_text(family = "黑體-繁 中黑", size = 14), legend.background = element_rect(fill = "gray96",colour = "gray88"), plot.background = element_rect(fill = "gray99"), plot.title = element_text(hjust = 0.5,size = 16), #標題置中 strip.background = element_rect(fill = "lightgray", colour = NA) ) |
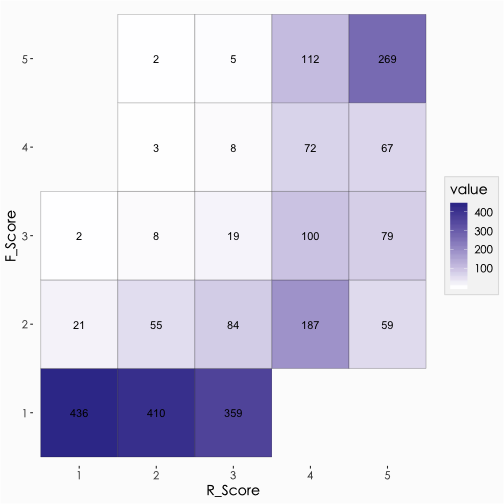
根據行銷目的斟酌參考R_ScorexM_Score和R_ScorexF_Score交叉資訊表,有了基本分群資訊後,就可套用各客群歷史行銷回應率資訊,來輔助分配行銷預算,尋找目標客群,並估算預期行銷效果(預期回應人數與投報率)。
更多統計分析(Analysis)與資料分群(Clustering)學習筆記:
- 開發一個免費App能賺多少錢?靠AdMob廣告月收3萬實例分享
- Partitional Clustering 切割式分群 | K-means, Kmedoid | Clustering 資料分群
- Hierarchical Clustering 階層式分群 | Clustering 資料分群 | R 統計
- Decision Tree 決策樹 | CART, Conditional Inference Tree, Random Forest
參考資料連結: